It seems as though I missed release notes for version RSiteCatalyst 1.4.6, so we’ll do those and RSiteCatalyst 1.4.7 (now on CRAN) and the same time…
RSiteCatalyst 1.4.6
This release was mostly tweaking some settings, specifically:
Adding a second top argument within the Queue* functions for more control on results returned. It used to be the case that a breakdown report with the top argument would return, say, the top 10 values of the first variable and up to 50,000 values for the breakdown. Now you can control the second level breakdown as well, such as the top 10 pages and top 5 browsers for those pages.
Disable checking of the API call before submitting. I never ran into this, but a user was seeing that the API would return errors in validation under high volume. So if you have any weird issues, disable validation using the validate = FALSE keyword argument.
The package now handles situation where API returns an unexpected type for the reportID and automatically converts it to the proper type (low-level issue, not a user-facing issue)
Those changes carry forward into version RSiteCatalyst 1.4.7, so there is no reason for a user to stick with this release.
RSiteCatalyst 1.4.7 - No more Unicode Errors!
I was surprised it took so long for someone to report this error, but #151 finally reported a case from a user in Germany where search keywords were being mangled due to the presence of an umlaut. UTF-8 encoding is now the default for both calling the API and processing the results, so this issue will hopefully not arise again.
Additionally, a locale argument has been added, to set the proper locale for your report suite. This is specified through the SCAuth() function, with the list of possible locales provided by the Adobe documentation. So if the even after using 1.4.7 with UTF-8 encoding by default, you are still seeing errors, try setting the locale to the country you are in/country setting of the report suite.
Feature Requests/Bugs
As always, if you come across bugs or have feature requests, please continue to use RSiteCatalyst GitHub Issues page to submit issues. Don’t worry about cluttering up the page with tickets, please fill out a new issue for anything you encounter (with code you’ve already tried and is failing), unless you are SURE that it is the same problem someone else is facing.
However, outside of patching really serious bugs, I will likely not spend any more time improving this package in the future; my interests have changed, and RSiteCatalyst is pretty much complete as far as I’m concerned. That said, contributors are also very welcomed. If there is a feature you’d like added, and especially if you can fix an outstanding issue reported at GitHub, we’d love to have your contributions. Willem and I are both parents of young children and have real jobs outside of open-source software creation, so we welcome any meaningful contributions to RSiteCatalyst that anyone would like to contribute.
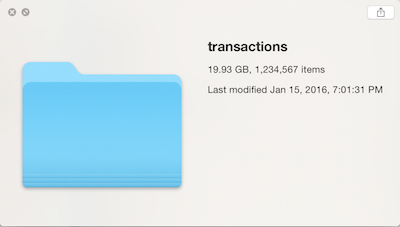
More often that I would like, I receive datasets where the data has only been partially cleaned, such as the picture on the right: hundreds, thousands…even millions of tiny files. Usually when this happens, the data all have the same format (such as having being generated by sensors or other memory-constrained devices).
The problem with data like this is that 1) it’s inconvenient to think about a dataset as a million individual pieces 2) the data in aggregate are too large to hold in RAM but 3) the data are small enough where using Hadoop or even a relational database seems like overkill.
Surprisingly, with judicious use of GNU Parallel, stream processing and a relatively modern computer, you can efficiently process annoying, “medium-sized” data as described above.
Data Generation
For this blog post, I used a combination of R and Python to generate the data: the “Groceries” dataset from the arules package for sampling transactions (with replacement), and the Python Faker (fake-factory) package to generate fake customer profiles and for creating the 1MM+ text files:
#R Code
library(arules)data("Groceries")write(Groceries,"groceries.txt",sep=",")#Python Code
importrandom,csvfromfakerimportFakerfake=Faker()frompandasimportDataFrameimportpandasaspd# Create customer file of 1,234,567 customers with fake data
# Use dataframe index as a way to generate unique customer id
customers=[fake.simple_profile()forxinrange(0,1234567)]customer_df=pd.DataFrame(customers)customer_df["cust_id"]=customer_df.index#Read in transactions file from arules package
withopen("grocerydata.txt")asf:transactions=f.readlines()#Remove new line character
transactions=[x[0:-1]forxintransactions]#Generate transactions by cust_id
#file format:
#cust_id::int
#store_id::int
#transaction_datetime::string/datetime
#items::string
#for each customer...
foriinrange(0,1234567):#...create a file...
withopen('/transactions/custfile_%s'%i,'w')ascsvfile:trans=csv.writer(csvfile,delimiter=' ',quotechar='"',quoting=csv.QUOTE_MINIMAL)#...that contains all of the transactions they've ever made
forjinrange(1,random.randint(1,365)):trans.writerow([i,fake.zipcode(),fake.date_time_this_decade(before_now=True,after_now=False),transactions[random.randint(0,len(transactions)-1)]])
Problem 1: Concatenating (cat * >> out.txt ?!)
The cat utility in Unix-y systems is familiar to most anyone who has ever opened up a Terminal window. Take some or all of the files in a folder, concatenate them together….one big file. But something funny happens once you get enough files…
$ cat*>> out.txt
-bash: /bin/cat: Argument list too long
That’s a fun thought…too many files for the computer to keep track of. As it turns out, many Unix tools will only accept about 10,000 arguments; the use of the asterisk in the cat command gets expanded before running, so the above statement passes 1,234,567 arguments to cat and you get an error message.
One (naive) solution would be to loop over every file (a completely serial operation):
for f in*;do cat"$f">> ../transactions_cat/transactions.csv;done
Roughly 10,093 seconds later, you’ll have your concatenated file. Three hours is quite a coffee break…
Solution 1: GNU Parallel & Concatenation
Above, I mentioned that looping over each file gets you past the error condition of too many arguments, but it is a serial operation. If you look at your computer usage during that operation, you’ll likely see that only a fraction of a core of your computer’s CPU is being utilized. We can greatly improve that through the use of GNU Parallel:
ls | parallel -m-j$f"cat {} >> ../transactions_cat/transactions.csv"
The $f argument in the code is to highlight that you can choose the level of parallelism; however, you will not get infinitely linear scaling, as shown below (graph code, Julia):
Given that the graph represents a single run at each level of parallelism, it’s a bit difficult to say exactly where the parallelism gets maxed out, but at roughly 10 concurrent jobs, there’s no additional benefit. It’s also interesting to point out what the -m argument represents; by specifying m, you allow multiple arguments (i.e. multiple text files) to be passed as inputs into parallel. This alone leads to an 8x speedup over the naive loop solution.
Problem 2: Data > RAM
Now that we have a single file, we’ve removed the “one million files” cognitive dissonance, but now we have a second problem: at 19.93GB, the amount of data exceeds the RAM in my laptop (2014 MBP, 16GB of RAM). So in order to do analysis, either a bigger machine is needed or processing has to be done in a streaming or “chunked” manner (such as using the “chunksize” keyword in pandas).
But continuing on with our use of GNU Parallel, suppose we wanted to answer the following types of questions about our transactions data:
How many unique products were sold?
How many transactions were there per day?
How many total items were sold per store, per month?
If it’s not clear from the list above, in all three questions there is an “embarrassingly parallel” portion of the computation. Let’s take a look at how to answer all three of these questions in a time- and RAM-efficient manner:
Q1: Unique Products
Given the format of the data file (transactions in a single column array), this question is the hardest to parallelize, but using a neat trick with the [tr](http://www.linfo.org/tr.html) (transliterate) utility, we can map our data to one product per row as we stream over the file:
# Serial method (i.e. no parallelism)# This is a simple implementation of map & reduce; tr statements represent one map, sort -u statements one reducer# cut -d ' ' -f 5- transactions.csv | \ - Using cut, take everything from the 5th column and over from the transactions.csv file# tr -d \" | \ - Using tr, trim off double-quotes. This leaves us with a comma-delimited string of products representing a transaction# sort -u | \ - Using sort, put similar items together, but only output the unique values# wc -l - Count number of unique lines, which after de-duping, represents number of unique products$ time cut-d' '-f 5- transactions.csv | tr-d\" | tr',''\n' | sort-u | wc-l
331
real 292m7.116s
# Parallelized version, default chunk size of 1MB. This will use 100% of all CPUs (real and virtual)# Also map & reduce; tr statements a single map, sort -u statements multiple reducers (8 by default)$ time cut-d' '-f 5- transactions.csv | tr-d\" | tr',''\n' | parallel --pipe--block 1M sort-u | sort-u | wc-l
331
# block size performance - Making block size smaller might improve performance# Number of jobs can also be manipulated (not evaluated)# --500K: 73m57.232s# --Default 1M: 75m55.268s (3.84x faster than serial)# --2M: 79m30.950s# --3M: 80m43.311s
The trick here is that we swap the comma-delimited transactions with the newline character; the effect of this is taking a single transaction row and returning multiple rows, one for each product. Then we pass that down the line, eventually using sort -u to de-dup the list and wc -l to count the number of unique lines (i.e. products).
In a serial fashion, it takes quite some time to calculate the number of unique products. Incorporating GNU Parallel, just using the defaults, gives nearly a 4x speedup!
Q2. Transactions By Day
If the file format could be considered undesirable in question 1, for question 2 the format is perfect. Since each row represents a transaction, all we need to do is perform the equivalent of a SQL Group By on the date and sum the rows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Data is at transaction level, so just need to do equivalent of 'group by' operation# Using cut again, we choose field 3, which is the date part of the timestamp# sort | uniq -c is a common pattern for doing a 'group by' count operation# Final tr step is to trim the leading quotation mark from date stringtime cut-d' '-f 3 transactions.csv | sort | uniq-c | tr-d\"
real 76m51.223s
# Parallelized version# Quoting can be annoying when using parallel, so writing a Bash function is often much easier than dealing with escaping quotes# To do 'group by' operation using awk, need to use an associative array# Because we are doing parallel operations, need to pass awk output to awk again to return final counts
awksub (){awk'{a[$3]+=1;}END{for(i in a)print i" "a[i];}';}export-f awksub
time parallel --pipe awksub < transactions.csv | awk'{a[$1]+=$2;}END{for(i in a)print i" "a[i];}' | tr-d\" | sort
real 8m22.674s (9.05x faster than serial)
Using GNU Parallel starts to become complicated here, but you do get a 9x speed-up by calculating rows by date in chunks, then “reducing” again by calculating total rows by date (a trick I picked up at this blog post.
Q3. Total items Per store, Per month
For this example, it could be that my command-line fu is weak, but the serial method actually turns out to be the fastest. Of course, at a 14 minute run time, the real-time benefits to parallelization aren’t that great.
It may be possible that one of you out there knows how to do this correctly, but an interesting thing to note is that the serial version already uses 40-50% of the available CPU available. So parallelization might yield a 2x speedup, but seven minutes extra per run isn’t worth spending hours trying to the optimal settings.
But, I’ve got MULTIPLE files…
The three examples above showed that it’s possible to process datasets larger than RAM in a realistic amount of time using GNU Parallel. However, the examples also showed that working with Unix utilities can become complicated rather quickly. Shell scripts can help move beyond the “one-liner” syndrome, when the pipeline gets so long you lose track of the logic, but eventually problems are more easily solved using other tools.
The data that I generated at the beginning of this post represented two concepts: transactions and customers. Once you get to the point where you want to do joins, summarize by multiple columns, estimate models, etc., loading data into a database or an analytics environment like R or Python makes sense. But hopefully this post has shown that a laptop is capable of analyzing WAY more data than most people believe, using many tools written decades ago.
To end 2015, I decided to finally learn C, instead of making it a 2016 resolution! I had previously done the ‘Learn C The Hard Way’ tutorials, taken about a year off, and thus forgotten everything.
Rather than re-do the same material, I decided to get ’21st Century C’ from O’Reilly and work through that. Unfortunately, there is an error/misprint in the very beginning chapters that makes doing the exercises near impossible on OSX. This error manifests itself as c99: invalid argument 'all' to -W Error 64. If you encounter this error on OSX (I’m using OSX 10.11.2 El Capitan as of writing this post), here are three methods for fixing the issue.
Error 64!
When the discussion of using Makefiles begins on page 15, there is a discussion of the “smallest practicable makefile”, which is just six lines long:
Unfortunately, this doesn’t quite work on OSX. Page 11 in the book sort-of references that a fix is needed, but the directions aren’t so clear…
Error 64, solution 1: Book Fix, updated
To use the book fix, you are supposed to:
Create a file named c99
Put the lines gcc -std=c99 $\* OR clang $\* in the c99 file
Add the file to your PATH in Terminal (such as export PATH="/Users/computeruser:$PATH" if the c99 file were located in /Users/computeruser directory)
Run chmod +x c99 on the file to make it executable
Once you add this work-around to your PATH, then open a fresh Terminal window (or run source .bash_profile to refresh the Bash settings), you should be able to use Make to compile your C code.
But to be honest, this seems like a really weird “fix” to me, as it overrides the C compiler settings for any program run via Terminal. I prefer one of two alternate solutions.
Error 64, solution 2: Makefile Change
As I was researching this, a helpful Twitter user noted:
@randyzwitch Remove space between CFLAGS and =, and replace c99 with cc. See man c99, -W is not -Wwarnings.
The final solution I came across is rather than using the GCC compiler, you can use an alternate compiler called Clang, which is also generally available on OSX (especially with XCode installed). Like solution 2 above, the Makefile is just subtlety different:
Whether to use GCC or Clang as your compiler is really beyond the scope of this blog post; as 21st Century C discusses, it really shouldn’t matter (especially when you are just learning the mechanics of the language).
Error 64, Be Gone!
There’s not really much more to say at this point; this blog post is mainly documentation for anyone who comes across this error in the future. I’ve continued on through the book using Clang, but suffice to say, it’s not the compiler that writes poor-quality, non-compiling code, it’s the user. Ah, the fun of learning 🙂