As digital marketers & analysts, we’re often asked to quantify when a metric goes beyond just random variation and becomes an actual “unexpected” result. In cases such as A/B..N testing, it’s easy to calculate a t-test to quantify the difference between two testing populations, but for time-series metrics, using a t-test is likely not appropriate.
To determine whether a time-series has become “out-of-control”, we can use Exponential Smoothing to forecast the Expected Value, as well as calculate Upper Control Limits (UCL) and Lower Control Limits (LCL). To the extent a data point exceeds the UCL or falls below the LCL, we can say that statistically a time-series is no longer within the expected range. There are numerous ways to create time-series models using R, but for the purposes of this blog post I’m going to focus on Exponential Smoothing, which is how the anomaly detection feature is implemented within the Adobe Analytics API.
Holt-Winters & Exponential Smoothing
There are three techniques that the Adobe Analytics API uses to build time-series models:
The formulas behind each of the techniques are easily found elsewhere, but the main point behind the three techniques is that time-series data can have a long-term trend (Double Exponential Smoothing) and/or a seasonal trend (Triple Exponential Smoothing). To the extent that a time-series has a seasonal component, the seasonal component can be additive (a fixed amount of increase across the series, such as the number of degrees increase in temperature in Summer) or multiplicative (a multiplier relative to the level of the series, such as a 10% increase in sales during holiday periods).
The Adobe Analytics API simplifies the choice of which technique to use by calculating a forecast using all three methods, then choosing the method that has the best fit as calculated by the model having the minimum (squared) error. It’s important to note that while this is probably an okay model selection method for detecting anomalies, this method does not guarantee that the model chosen is the actual “best” forecast model to fit the data.
RSiteCatalyst API call
Using the RSiteCatalyst R package version 1.1, it’s trivial to access the anomaly detection feature:
1
2
3
4
5
6
7
8
9
10
11
12
#Run until version > 1.0 on CRANlibrary(devtools)install_github("RSiteCatalyst","randyzwitch",ref="master")#Run if version >= 1.1 on CRANlibrary("RSiteCatalyst")#API AuthenticationSCAuth(<username:company>,<shared_secret>)#API function callpageviews_w_forecast<-QueueOvertime(reportSuiteID=<reportsuite>,dateFrom="2013-06-01",dateTo="2013-08-13",metrics="pageviews",dateGranularity="day",anomalyDetection="1")
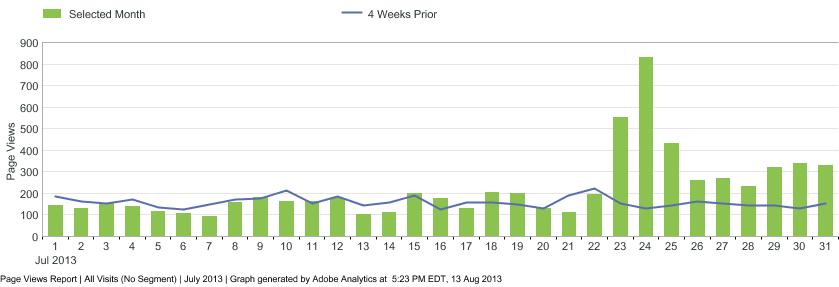
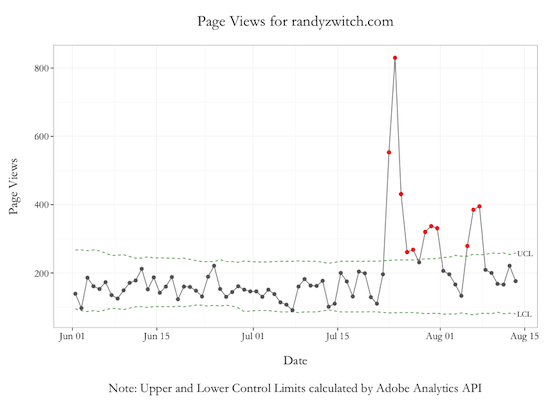
Once the function call is run, you will receive a DataFrame of ‘Day’ granularity with the actual metric and three additional columns for the forecasted value, UCL and LCL. Graphing these data using ggplot2 (Graph Code Here - GitHub Gist), we can now see on which days an anomalous result occurred:
The red dots in the graph above indicate days where page views either exceeded the UCL or fell below the LCL. On July 23 - 24 timeframe, traffic to this blog spiked dramatically due to a blog post about the Julia programming language, and continued to stay above the norm for about a week afterwards.
Anomaly Detection Limitations
There two limitations to keep in mind when using the Anomaly Detection feature of the Adobe Analytics API:
Anomaly Detection is currently only available for ‘Day’ granularity
Forecasts are built on 35 days of past history
In neither case do I view these limitations as dealbreakers. The first limitation is just an engineering decision, which I’m sure could be expanded if enough people used this functionality.
For the time period of 35 days to build the forecasts, this is an area where there is a balance between calculation time vs. capturing a long-term and/or seasonal trend in the data. Using 35 days as your time period, you get five weeks of day-of-week seasonality, as well as 35 points to calculate a ‘long-term’ trend. If the time period is of concern in terms of what constitutes a ‘good forecast’, then there are plenty of other techniques that can be explored using R (or any other statistical software for that matter).
Elevating the discussion
I have to give a hearty ‘Well Done!’ to the Adobe Analytics folks for elevating the discussion in terms of digital analytics. By using statistical techniques like Exponential Smoothing, analysts can move away from qualitative statements like “Does it look like something is wrong with our data?” to actually quantifying when KPIs are “too far” away from the norm and should be explored further.
Importing tabular data into Julia can be done in (at least) three ways: reading a delimited file into an array, reading a delimited file into a DataFrame and accessing databases using ODBC.
Reading a file into an array using readdlm
The most basic way to read data into Julia is through the use of the readdlm function, which will create an array:
1
readdlm(source,delim::Char,T::Type;options...)
If you are reading in a fairly normal delimited file, you can get away with just using the first two arguments, source and delim:
It’s important to note that by only specifying the first two arguments, you leave it up to Julia to determine the type of array to return. In the code example above, an array of type Any is returned, as the .csv file I read in was not of homogenous type such as Int64 or ASCIIString. If you know for certain which type of array you want, you specify the data type using the type argument:
It’s probably the case that unless you are looking to do linear algebra or other specific mathy type work, you’ll likely find that reading your data into a DataFrame will be more comfortable to work with (especially if you are coming from an R, Python/pandas or even spreadsheet tradition).
To write an array out to a file, you can use the writedlm function (defaults to comma-separated):
1
writedlm(filename,array,delim::Char)
Reading a file into a DataFrame using readtable
As I covered in my prior blog post about Julia, you can also read in delimited files into Julia using the DataFrames package, which returns a DataFrame instead of an array. Besides just being able to read in delimited files, the DataFrames package also supports reading in gzippped files on the fly:
From what I understand, in the future you will be able to read files directly from Amazon S3 into a DataFrame (this is already supported in the AWS package), but for now, the DataFrames package works only on local files. Writing a DataFrame to file can be done with the writetable function:
1
writetable(filename::String,df::DataFrame)
By default, the writetable function will use the delimiter specified by the filename extension and default to printing the column names as a header.
Accessing Databases using ODBC
The third major way of importing tabular data into Julia is through the use of ODBC access to various databases such as MySQL and PostgreSQL.
Using a DSN
The Julia ODBC package provides functionality to connect to a database using a Data Source Name (DSN). Assuming you store all the credentials in your DSN (server name, username, password, etc.), connecting to a database is as easy as:
Of course, if you don’t want to store your password in your DSN (especially in the case where there are multiple users for a computer), you can pass the usr and pwd arguments to the ODBC.connect function:
1
ODBC.connect(dsn;usr="",pwd="")
Using a connection string
Alternatively, you can build your own connection strings within a Julia session using the advancedconnect function:
Regardless of which way you connect, you can query data using the query function. If you want your output as a DataFrame, you can assign the result of the function to an object. If you want to save the results to a file, you specify the file argument:
1
2
3
4
5
6
7
8
9
10
11
12
13
julia>usingODBCjulia>ODBC.connect("MySQL")Connection1toMySQLsuccessful.#Save query results into a DataFrame called 'results'julia>results=query("Select * from a1987;");julia>typeof(results)DataFrame(usemethods(DataFrame)toseeconstructors)#Save query results to a file, tab-delimited (default)julia>query("Select * from a1987;",file="output.tab",delim='\t');
Summary
Overall, importing data into Julia is no easier/more difficult than any other language. The biggest thing I’ve noticed thus far is that Julia is a bit less efficient than Python/pandas or R in terms of the amount of RAM needed to store data. In my experience, this is really only an issue once you are working with 1GB+ files (of course, depending on the resources available to you on your machine).
In a previous rant about data science & innovation, I made reference to a problem I’m having at work where I wanted to classify roughly a quarter-billion URLs by predicted website content (without having to actually visit the website). A few colleagues have asked how you go about even starting to solve a problem like that, and the answer is massively parallel processing.
Attacking the problem using a local machine
In order to classify the URLs, the first thing that’s needed is a customized dictionary of words relative to our company’s subject matter. When you have a corpus of words that are already defined (such as a digitized book), finding the population of words is relatively simple: split the text based on spaces & punctuation and you’re more or less done. However, with a URL, you have one continuous string with no word boundaries. One way to try and find the boundaries would be the following in Python:
importcollectionsimportnltk#Dictionary from Unix
internal_dict=open("/usr/share/dict/words")#Stopwords corpus from NLTK
stopwords=nltk.corpus.stopwords.words('english')#Build english_dictionary of prospect words
english_dictionary=[]forlineininternal_dict:iflinenotinstopwordsandlen(line)>4:#make sure only "big", useful words included
english_dictionary.append(line.rstrip('\n'))#How many words are in the complete dictionary?
len(english_dictionary)#Import urls
urls=[lineforlineinopen("/path/to/urls/file.csv")]#Build counter dictionary
wordcount=collections.Counter()forwordinenglish_dictionary:#Loop over all possible English words
forurlinurls:#Loop over all urls in list
ifwordinurl:wordcount[word]+=1#Once word found, add to dictionary counter
The problem with approaching the word searching problem in this manner is you are limited to the power of your local machine. In my case with a relatively new MacBook Pro, I can process 1,000 lines in 19 seconds as a single-threaded process. At 250,000,000 URLs, that’s 4.75 million seconds…197,916 minutes…3,298 hours…137 days…4.58 months! Of course, 4.58 months is for the data I have now, which is accumulating every second of every day. Clearly, to find just the custom dictionary of words, I’ll need to employ MANY more computers/tasks.
Amazon ElasticMapreduce = Lots of Horsepower
One thing you might notice about the Python code above is that the two loops have no real reason to be run serially; each comparison of URL and dictionary word can be run independently of each other (often referred to as “embarrassingly parallel”). This type of programming pattern is one that is well suited to running on a Hadoop cluster. With Amazon ElasticMapReduce (EMR), we can provision tens, hundreds, even thousands of computer instances to process this URL-dictionary word comparison, and thus getting our answer much faster. The one downside of using Amazon EMR to access Hadoop is that EMR expects to get a Java ``.jar` file containing your MapReduce code. Luckily, there is a Python package called MRJob that does the Python-to-Java translation automatically, so that users don’t have to switch languages to get massively parallel processing.
Writing MapReduce code
The Python code above, keeping a tally of words & number of occurrences IS a version of the MapReduce coding paradigm. Going through the looping process to do the comparison is the “Map” portion of the code and the sum of the word values is the “Reduce” step. However, in order to use EMR, we need to modify the above code to remove the outer URL loop:
The reason why we remove the outer loop that loops over the lines of the URL file is because that is implicit to the EMR/Hadoop style of processing. We will specify a file that we want to process in our Python script, then EMR will distribute the URLs file across all the Hadoop nodes. Essentially, our 250,000,000 million lines of URLs will become 1,000 tasks of length 250,000 urls (assuming 125 nodes of 8 tasks each).
Calling EMR from the Python command line
Once we have our Python MRJob code written, we can submit our code to EMR from the command line. Here’s what an example code looks like:
There are many more options that are possible for the MRJob package, so I highly suggest that you read the documentation for EMR options. One thing to also note is that MRJob uses a configuration file to host various options for EMR called “runners”. Yelp (the maker of the MRJob package) has posted an example of the mrjob.conf file with the most common options to use. In this file, you can specify your Amazon API keys, the type of instances you want to use (I use c1.xlarge spot instances for the most part), where your SSH keys are located and so on.
Results
In terms of performance, I have 8 files of 5GB’s each of URLs (~17.5 million lines per file) that I’m running through the MRJob code above. The first file was run with 19 c1.xlarge instances, creating on average 133 mappers and 65 reducers and taking 917 minutes (3.14 seconds/1000 lines). The second file was run with 80 c1.xlarge instances, creating 560 mappers and 160 reducers and taking 218 minutes (0.75 seconds/1000 lines). So using four times as many instances leads to one-fourth of the run-time.
For the most part, you can expect linear performance in terms of adding nodes to your EMR cluster. I know at some point, Hadoop will decide that it no longer needs to add any more mappers/reducers, but I haven’t had the desire to find out exactly how many I’d need to add to get to that point! 🙂