We’ve finally made it to the final post in this tutorial! In my prior posts about getting started with Hadoop, we’ve covered the entire lifecycle from how to set up a small cluster using Amazon EC2 and Cloudera through how to load data using Hue. With our data loaded in HDFS, we can finally move on to the actual analysis portion of the airline dataset using Hive and Pig.
Basic Descriptive Statistics Using Hive
In part 4 of this tutorial, we used a Hive script to create a view named “vw_airline” to hold all of our airline data. Running a simple query is as easy as running the following in the Hive window in Hue. Note that this is ANSI-standard SQL code, even though we are submitting it using Hive:
A simple query like this is a great way to get a feel for the table, including determining whether or not the files were loaded correctly. Once the results are displayed, you can create simple visualizations like bar charts, line plots, scatterplots and pie charts. The results of the following query are shown below. Knowing this dataset, I can tell that the files were loaded incorrectly; the dips at Years 1994 and 2004 are too few records and will need to be reloaded.
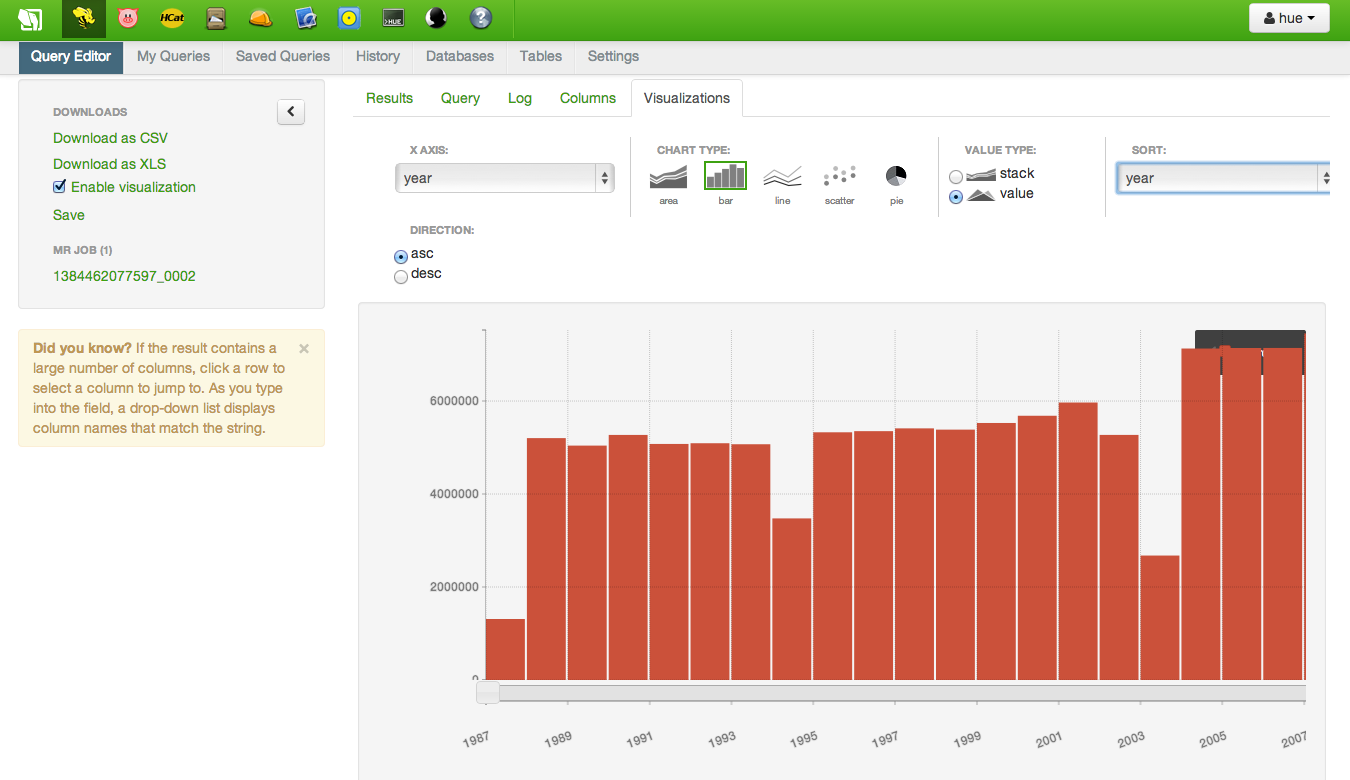
1994 and 2004 have too few rows, which was validated using wc -l 1994.csv at the command line (outside of Hadoop)
Besides just simple counts, Hive supports nearly all standard SQL syntax relative to functions such as SUM, COUNT, MIN, MAX, etc., table joins, user-defined functions (UDF)`, window functions…pretty much everything that you are used to from other SQL tools. AFAIK, the only thing that Hive doesn’t support is nested sub-queries, but that’s on the Stinger initiative for improving Hive. However, depending on the nested subquery being performed, you might be able to accomplish the same thing using a LEFT SEMI JOIN.
Using Pig for Analytics
It’s important to realize that Hadoop isn’t just another RDBMS where you run SQL. Using Pig, you can write scripts for calculation in a similar manner to using other high-level languages such as Python or R.
For example, suppose we wanted to calculate the average distance for each route. A Pig script to calculate this might look like the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
--Load data from view to use
air = LOAD 'default.vw_airline' USING org.apache.hcatalog.pig.HCatLoader();
--Use FOREACH to limit data to origin, dest, distance
--Concatentate origin and destination together, separated by a pipe
--CONCAT appears to only allow two arguments, which is why the function is called twice (to allow 3 arguments)
origindest = FOREACH air generate CONCAT(origin, CONCAT('|' , dest)) as route, distance;
--Group origindest dataset by route
groupedroutes = GROUP origindest BY (route);
--Calculate average distance by route
avg_distance = FOREACH groupedroutes GENERATE group, AVG(origindest.distance);
--Show results in Pig shell
dump avg_distance;
--Write out results to text file, separated by tab (default)
store avg_distance into '/user/hue/avg_distance';
While it is possible to calculate average distance using Hive and a GROUP BY statement, one of the benefits to using Pig is having control over every step of the data flow. So while Hive queries tend to answer a single question at a time, Pig allows an analyst to chain together any number of steps in a data flow. In the example above, we could pass the average distance for each route to another transformation, join it back to the original dataset or do anything else our analyst minds can imagine!
Summary
Over these five blog posts, I’ve outlined how to get started with Hadoop and ‘Big Data’ using Amazon and Cloudera/Hortonworks. Hopefully I’ve been able to demystify the concepts and terminology behind Hadoop, shown that setting up a Hadoop using Cloudera on Amazon EC2 isn’t unsurmountable, and loading data and analyzing it using Hive and Pig isn’t dramatically different than using SQL on other database systems you may have encountered in the past.
While there’s a lot of hype around ‘Big Data’, data sizes aren’t going to be getting any smaller in the future. So spend the $20 in AWS charges and build a Hadoop cluster! There’s no better way to learn than by doing…