In part 2 of the “Getting Started Using Hadoop” series, I discussed how to build a Hadoop cluster on Amazon EC2 using Cloudera CDH. This post will cover how to get your data into the Hadoop Distributed File System (HDFS) using the publicly available “Airline Dataset”. While there are multiple ways to upload data into HDFS, this post will only cover the easiest method, which is to use the Hue ‘File Browser’ interface.
Loading data into HDFS using Hue
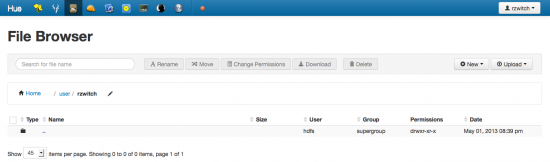
'File Browser' in Hue (Cloudera)
Loading data into Hadoop using Hue is by far the easiest way to get started. Hue provides a GUI that provides a “File Browser” like you normally see in Windows or OSX. The workflow here would be to download each year of Airline data to your local machine, then upload each file using the Upload -> Files menu drop-down.
While downloading files from one site on the Internet, then uploading files to somewhere else on the Internet is somewhat wasteful of time and bandwidth, as a tutorial to get started with Hadoop this isn’t the worst thing in the world. For those of you who are OSX users and comfortable using Bash from the command line, here’s some code so you don’t have to babysit the download process:
1
2
3
4
5
$ for i in {1987..2008}
> do
> curl http://stat-computing.org/dataexpo/2009/$i.csv.bz2 > $i.csv.bz2
> bunzip2 $i.csv.bz2
> done
Because you are going to be uploading a bunch of text files to your Hadoop cluster, I’d recommend zipping the files prior to upload. It doesn’t matter if you use .zip or .gz files with one key distinction: if you use .zip files, you will upload using the “Zip Files” button in the File Browser; if you choose .gz, then you must use the “Files” line in the File Browser. Not only will zipping the files make the upload faster, but it will also make sure you only need to do the process once (as opposed to hitting the upload button on each file). Using the .zip file upload process, you should something like the following…a new folder with all of the files extracted automatically:
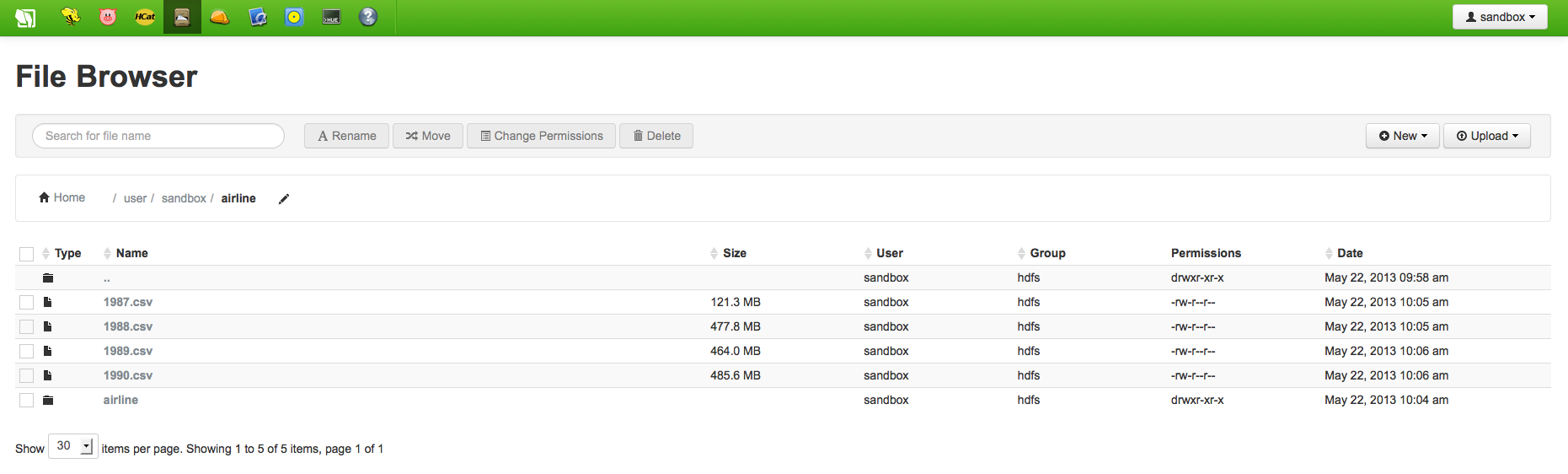
.zip file automatically extracted into folder with files (Hortonworks)
Next Steps
With the airline .csv files loaded for each year, we can use Pig or Hive to load the tables into a master dataset & schema. That will be the topic of the next tutorial.