While much of the focus in the Julia community has been on the performance aspects of Julia relative to other scientific computing languages, Julia is also perfectly suited to ‘glue’ together multiple data sources/languages. In this blog post, I will cover how to create an interactive plot using Gadfly.jl, by first preparing the data using Hadoop and Teradata Aster via ODBC.jl.
The example problem I am going to solve is calculating and visualizing the number of airplanes by hour in the air at any given time in the U.S. for the year 1987. Because of the structure and storage of the underlying data, I will need to write some custom Hive code, upload the data to Teradata Aster via a command-line utility, re-calculate the number of flights per hour using a built-in Aster function, then using Julia to visualize the data.
Step 1: Getting Data From Hadoop
In a prior set of blog posts, I talked about loading the airline dataset into Hadoop, then analyzing the dataset using Hive or Pig. Using ODBC.jl, we can use Hive via Julia to submit our queries. The hardest part of setting up this process is making sure that you have the appropriate Hive drivers for your Hadoop cluster and credentials (which isn’t covered here). Once you have your DSN set up, running Hive queries is as easy as the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
using ODBC
#Connect to Hadoop cluster via Hive (pre-defined Windows DSN in ODBC Manager)
hiveconn = ODBC.connect("Production hiveserver2"; usr="your-user-name", pwd="your-password-here")
#Clean data, return results directly to file
#Data returned with have origin of flight, flight takeoff, flight landing and elapsed time
hive_query_string =
"select
origin,
from_unixtime(flight_takeoff_datetime_origin) as flight_takeoff_datetime_origin,
from_unixtime(flight_takeoff_datetime_origin + (actualelapsedtime * 60)) as flight_landing_datetime_origin,
actualelapsedtime
from
(select
origin,
unix_timestamp(CONCAT(year,\"-\", month, \"-\", dayofmonth, \" \", SUBSTR(LPAD(deptime, 4, 0), 1, 2), \":\", SUBSTR(LPAD(deptime, 4, 0), 3, 4), \":\", \"00\")) as flight_takeoff_datetime_origin,
actualelapsedtime
from vw_airline
where year = 1987 and actualelapsedtime > 0) inner_query;"
#Run query, save results directly to file
query(hive_query_string, hiveconn;output="C:\\airline_times.csv",delim=',')
In this code, I’ve written my query as a Julia string, to keep my code easily modifiable. Then, I pass the Julia string object to the query() function, along with my ODBC connection object. This query runs on Hadoop through Hive, then streams the result directly to my local hard drive, making this a very RAM efficient (though I/O inefficient!) operation.
Step 2: Shelling Out To Load Data To Aster
Once I created the file with my Hadoop results in it, I now have a decision point: I can either A) do the rest of the analysis in Julia or B) use a different tool for my calculations. Because this is a toy example, I’m going to use Teradata Aster to do my calculations, which provides a convenient function called burst() to regularize timestamps into fixed intervals. But before I can use Aster to ‘burst’ my data, I first need to upload it to the database.
While I could loop over the data within Julia and insert each record one at a time, Teradata provides a command-line utility to upload data in parallel. Running command-line scripts from within Julia is as easy as using the run() command, with each command surrounded in backticks:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#Connect to Aster (pre-defined Windows DSN in ODBC Manager)
asterconn = ODBC.connect("aster01"; usr="your-user-name", pwd="your-password")
#Create table to hold airline results
create_airline_table_statement =
"create table ebi_temp.airline
(origin varchar,
flight_takeoff_datetime_origin timestamp,
flight_landing_datetime_origin timestamp,
actualelapsedtime int,
partition key (origin))"
#Execute query
query(create_airline_table_statement, asterconn)
#Create airport table
#Data downloaded from http://openflights.org/data.html
create_airport_table_statement =
"create table ebi_temp.airport
(airport_id int,
name varchar,
city varchar,
country varchar,
IATAFAA varchar,
ICAO varchar,
latitude float,
longitude float,
altitude int,
timezone float,
dst varchar,
partition key (country))"
#Execute query
query(create_airport_table_statement, asterconn)
#Upload data via run() command
#ncluster_loader utility already on Windows PATH
run(`ncluster_loader -h 192.168.1.1 -U your-user-name -w your-password -d aster01 -c --skip-rows=1 --el-enabled --el-table e_dist_error_2 --el-schema temp temp.airline C:\\airline_times.csv`)
run(`ncluster_loader -h 192.168.1.1 -U your-user-name -w your-password -d aster01 -c --el-enabled --el-table e_dist_error_2 --el-schema temp temp.airport C:\\airports.dat`)
While I could’ve run this at the command-line, having all of this within an IJulia Notebook keeps all my work together, should I need to re-run this in the future.
Step 3: Using Aster For Calculations
With my data now loaded in Aster, I can normalize the timestamps to UTC, then ‘burst’ the data into regular time intervals. Again, all of this can be done via ODBC from within Julia:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
#Normalize timestamps from local time to UTC time
aster_view_string = "
create view temp.vw_airline_times_utc as
select
row_number() over(order by flight_takeoff_datetime_origin) as unique_flight_number,
origin,
flight_takeoff_datetime_origin,
flight_landing_datetime_origin,
flight_takeoff_datetime_origin - (INTERVAL '1 hour' * timezone) as flight_takeoff_datetime_utc,
flight_landing_datetime_origin - (INTERVAL '1 hour' * timezone) as flight_landing_datetime_utc,
timezone
from temp.airline
left join temp.airport on (airline.origin = airport.iatafaa);"
#Execute query
query(aster_view_string, asterconn)
#Teradata Aster SQL-H functionality, accessed via ODBC query
burst_query_string =
"create table temp.airline_burst_hour distribute by hash (origin) as
SELECT
*,
\"INTERVAL_START\"::date as calendar_date,
extract(HOUR from \"INTERVAL_START\") as hour_utc
FROM BURST(
ON (select
unique_flight_number,
origin,
flight_takeoff_datetime_utc,
flight_landing_datetime_utc
FROM temp.vw_airline_times_utc
)
START_COLUMN('flight_takeoff_datetime_utc')
END_COLUMN('flight_landing_datetime_utc')
BURST_INTERVAL('3600')
);"
#Execute query
query(burst_query_string, asterconn)
Since it might not be clear what I’m doing here, the burst() function in Aster takes a row of data with a start and end timestamp, and (potentially) returns multiple rows which normalize the time between the timestamps. If you’re familiar with pandas in Python, it’s a similar functionality to resample on a series of timestamps.
Step 4: Download Smaller Data Into Julia, Visualize
Now that the data has been processed from Hadoop to Aster through a series of queries, we now have a much smaller dataset that can be loaded into RAM and processed by Julia:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#Calculate the number of flights per hour per day
flights_query = "
select
calendar_date,
hour_utc,
sum(1) as num_flights
from temp.airline_burst_hour
group by 1,2
order by 1,2;"
#Bring results into Julia DataFrame
flights_per_day = query(flights_query, asterconn)
using Gadfly
#Create boxplot, with one box plot per hour
set_default_plot_size(20cm, 12cm)
p = plot(flights_per_day , x="hour_utc", y="num_flights",
Guide.xlabel("Hour UTC"),
Guide.ylabel("Flights In Air"),
Guide.title("Number of Flights In Air To/From U.S. By Hour - 1987"),
Scale.y_continuous(minvalue=0, maxvalue=4000),
Geom.boxplot)
The Gadfly code above produces the following plot:
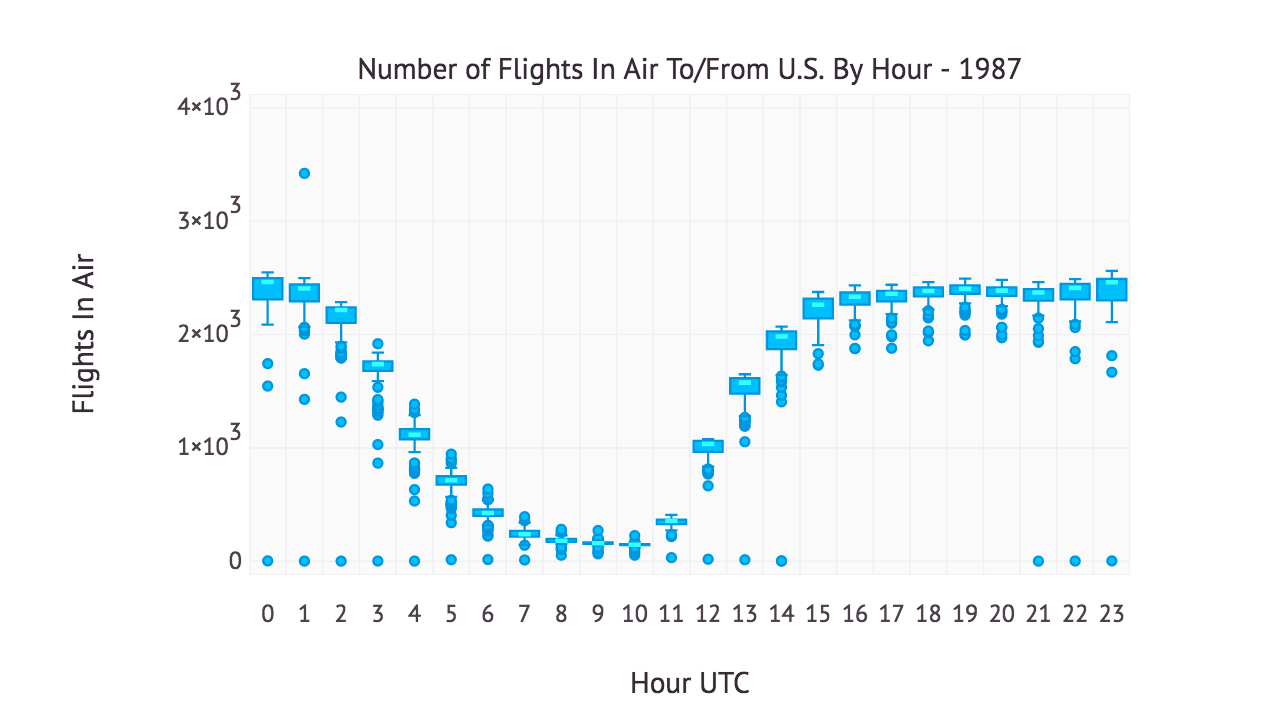
Since this chart is in UTC, it might not be obvious what the interpretation is of the trend. Because the airline dataset represents flights either leaving or returning to the United States, there are many fewer planes in the air overnight and the early morning hours (UTC 7-10, 2-5am Eastern). During the hours when the airports are open, there appears to be a limit of roughly 2500 planes per hour in the sky.
Why Not Do All Of This In Julia?
At this point, you might be tempted to wonder why go through all of this effort? Couldn’t this all be done in Julia?
Yes, you probably could do all of this work in Julia with a sufficiently large amount of RAM. As a proof-of-concept, I hope I’ve shown that there is much more to Julia than micro-benchmarking Julia’s speed relative to other scientific programming languages. You’ll notice that in none of my code have I used any type annotations, as none would really make sense (nor would they improve performance). And although this is a toy example purposely using multiple systems, I much more frequently use Julia in this manner at work than doing linear algebra or machine learning.
So next time you’re tempted to use Python or R or shell scripting or whatever, consider Julia as well. Julia is just as at-home as a scripting language as a scientific computing language.