One of the key tenets to doing impactful digital analysis is understanding what your visitors are trying to accomplish. One of the easiest methods to do this is by analyzing the words your visitors use to arrive on site (search keywords) and what words they are using while on the site (on-site search).
Although Google has made it much more difficult to analyze search keywords over the past several years (due to their passing of “(not provided)” instead of the actual keywords), we can create customer intent segments based on the keywords that are still being passed using unsupervised clustering methods such as k-means clustering.
Concept: K-Means Clustering/Unsupervised Learning
K-means clustering is one of many techniques within unsupervised learning that can be used for text analysis. Unsupervised refers to the fact that we’re trying to understand the structure of our underlying data, rather than trying to optimize for a specific, pre-labeled criterion (such as creating a predictive model for conversion). Unsupervised learning is a great technique for exploratory analysis in that the analyst enforces few assumptions on the data, so previously unexamined relationships can be determined then analyzed; contrast that with pre-defined relationships specified by the analyst (such as visitors from mobile or visitors from social), then evaluating how various metrics differ across these pre-defined groups.
Without getting too technical, k-means clustering is a method of partitioning data into ‘k’ subsets, where each data element is assigned to the closest cluster based on the distance of the data element from the center of the cluster. In order to use k-means clustering with text data, we need to do some text-to-numeric transformation of our text data. Luckily, R provides several packages to simplify the process.
Converting Text to Numeric Data: Document-Term Matrix
Since I use Adobe Analytics on this blog, I’m going to use the RSiteCatalyst package to get my natural search keywords into a dataframe. Once the keywords are in a dataframe, we can use the RTextTools package to create a document-term matrix, where each row is our search term and each column is a 1/0 representation of whether a single word is contained within natural search term.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#### 0. Setup
library("RSiteCatalyst")
library("RTextTools") #Loads many packages useful for text mining
#### 1. RSiteCatalyst code - Get Natural Search Keywords & Metrics
#Set credentials
SCAuth(<username:company>, <shared secret>)
#Get list of search engine terms
searchkeywords <- QueueRanked(<report_suite>, "2013-02-01","2013-09-16",
c("entries", "visits", "pageviews", "instances", "bounces"),
"searchenginenaturalkeyword", top="100000", startingWith = "1")
#### 2. Process keywords into format suitable for text mining
#Create document-term matrix, passing data cleaning options
#Stem the words to avoid multiples of similar words
#Need to set wordLength to minimum of 1 because "r" a likely term
dtm <- create_matrix(searchkeywords$'Natural Search Keyword',
stemWords=TRUE,
removeStopwords=FALSE,
minWordLength=1,
removePunctuation= TRUE)
Within the create_matrix function, I’m using four keyword arguments to process the data:
stemWordsreduces a word down to its root, which is a standardization method to avoid having multiple versions of words referring to the same concept (e.g. argue, arguing, argued reduces to ‘argu’)removeStopwordseliminates common English words such as “they”, “he” , “always”minWordLengthsets the minimum number of characters that constitutes a ‘word’, which I set to 1 because of the high likelihood of ‘r’ being a keywordremovePunctuationremoves periods, commas, etc.
Popular Words
If you are unfamiliar with the terms that might be contained in your dataset, you can use the findFreqTerms to see which terms occur with a minimum frequency. Here are the terms that occur at least 20 times on this blog:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
> #Inspect most popular words, minimum frequency of 20
> findFreqTerms(dtm, lowfreq=20)
[1] "15" "2008" "2009" "2011" "a" "ad" "add" "adsens"
[9] "air" "analyt" "and" "appl" "at" "back" "bezel" "black"
[17] "book" "bookmark" "break" "broke" "broken" "bubbl" "by" "can"
[25] "case" "chang" "child" "code" "comment" "comput" "cost" "cover"
[33] "crack" "css" "custom" "data" "delet" "disabl" "display" "do"
[41] "doe" "drop" "edit" "eleven" "em209" "entri" "fix" "footer"
[49] "footerphp" "for" "free" "from" "get" "glue" "googl" "hadoop"
[57] "header" "hing" "how" "i" "if" "imag" "in" "is"
[65] "it" "laptop" "late" "lcd" "lid" "link" "logo" "loos"
[73] "mac" "macbook" "make" "mobil" "modifi" "much" "my" "navig"
[81] "of" "off" "omnitur" "on" "page" "permalink" "php" "post"
[89] "power" "pro" "problem" "program" "proud" "r" "remov" "repair"
[97] "replac" "report" "sas" "screen" "separ" "site" "sitecatalyst" "store"
[105] "tag" "text" "the" "theme" "this" "tighten" "to" "top"
[113] "turn" "twenti" "twentyeleven" "uncategor" "unibodi" "use" "variabl" "version"
[121] "view" "vs" "warranti" "was" "what" "will" "with" "wordpress"
[129] "wp" "you"
Guessing at ‘k’: A First Run at Clustering
Once we have our data set up, we can very quickly run the k-means algorithm within R. The one downside to using k-means clustering as a technique is that the user must choose ‘k’, the number of clusters expected from the dataset. In absence of any heuristics about what ‘k’ to use, I can guess that there are five topics on this blog: 1. Data Science
- Digital Analytics
- R
- Julia
- WordPress
Running the following code, we can see if the algorithm agrees:
1
2
3
4
5
6
7
8
9
10
11
12
13
#I think there are 5 main topics: Data Science, Web Analytics, R, Julia, Wordpress
kmeans5<- kmeans(dtm, 5)
#Merge cluster assignment back to keywords
kw_with_cluster <- as.data.frame(cbind(searchkeywords$'Natural Search Keyword', kmeans5$cluster))
names(kw_with_cluster) <- c("keyword", "kmeans5")
#Make df for each cluster result, quickly "eyeball" results
cluster1 <- subset(kw_with_cluster, subset=kmeans5 == 1)
cluster2 <- subset(kw_with_cluster, subset=kmeans5 == 2)
cluster3 <- subset(kw_with_cluster, subset=kmeans5 == 3)
cluster4 <- subset(kw_with_cluster, subset=kmeans5 == 4)
cluster5 <- subset(kw_with_cluster, subset=kmeans5 == 5)
Opening the dataframes to observe the results, it seems that the algorithm disagrees:
- Cluster 1: “Free-for-All” cluster: not well separated (41.1% of terms)
- Cluster 2: “wordpress” and “remove” (4.9% of terms)
- Cluster 3: “powered by wordpress” (4.3% of terms)
- Cluster 4: “twenty eleven” (13.5% of terms)
- Cluster 5: “macbook” (36.2% of terms)
Of the clusters, the strongest cluster in terms of performance is cluster 5, which is pretty homogenous in terms of being about ‘macbook’ terms. Clusters 2-4 are all about WordPress, albeit different topics surrounding blogging. And cluster 1 is a large hodge-podge of terms that seem unrelated. Clearly, five clusters isn’t the proper value for ‘k’.
Selecting ‘k’ Using ‘Elbow Method’
Instead of randomly choosing values of ‘k’, then looking at each cluster result until we find one we like, we can take a more automated approach to picking ‘k’. For every kmeans object returned by R, there is a metric tot.withinss that provides the total of the squared distance metric for each cluster.
1
2
3
4
5
6
7
8
9
10
11
12
13
#accumulator for cost results
cost_df <- data.frame()
#run kmeans for all clusters up to 100
for(i in 1:100){
#Run kmeans for each level of i, allowing up to 100 iterations for convergence
kmeans<- kmeans(x=dtm, centers=i, iter.max=100)
#Combine cluster number and cost together, write to df
cost_df<- rbind(cost_df, cbind(i, kmeans$tot.withinss))
}
names(cost_df) <- c("cluster", "cost")
The cost_df dataframe accumulates the results for each run, which can then be plotted using ggplot2 (ggplot2 Gist here):
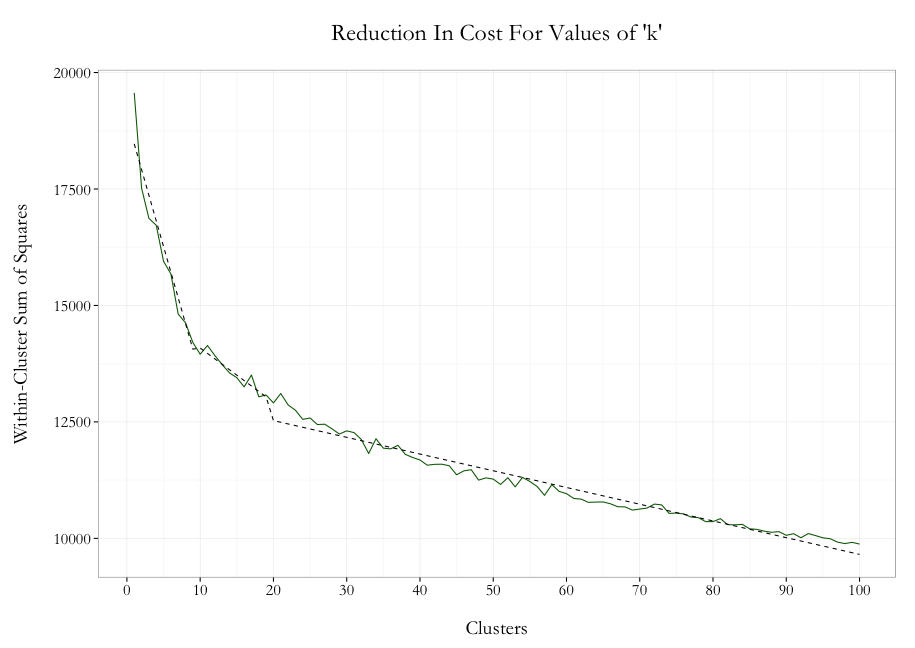
The plot above is a technique known informally as the ‘elbow method’, where we are looking for breakpoints in our cost plot to understand where we should stop adding clusters. We can see that the slope of the cost function gets flatter at 10 clusters, then flatter again around 20 clusters. This means that as we add clusters above 10 (or 20), each additional cluster becomes less effective at reducing the distance from the each data center (i.e. reduces the variance less). So while we haven’t determined an absolute, single ‘best’ value of ‘k’, we have narrowed down a range of values for ‘k’ to evaluate.
Ultimately, the best value of ‘k’ will be determined as a combination of a heuristic method like the ‘Elbow Method’, along with analyst judgement after looking at the results. Once you’ve determined your optimal cluster definitions, it’s trivial to calculate metrics such as Bounce Rate, Pageviews per Visit, Conversion Rate or Average Order Value to see how well the clusters actually describe different behaviors on-site.
Summary
K-means clustering is one of many unsupervised learning techniques that can be used to understand the underlying structure of a dataset. When used with text data, k-means clustering can provide a great way to organize the thousands-to-millions of words being used by your customers to describe their visits. Once you understand what your customers are trying to do, you can tailor your on-site experiences to match these needs, as well as adjusting your reporting/dashboards to monitor the various customer groups.
EDIT: For those who want to play around with the code but don’t use Adobe Analytics, here is the file of search keywords I used. Once you read in the .csv file into a dataframe and name it searchkeywords, you should be able to replicate everything in this blog post.