Edit 10/1/2018: When I wrote this blog post, the company and product were named MapD. I’ve changed the title to reflect the new company name, but left the MapD references below to hopefully avoid confusion
In my post Installing MapD on Microsoft Azure, I showed how to install MapD Community Edition on Microsoft Azure, using Ubuntu 16.04 LTS as the base image. One thing I glossed over during the firewall/security section was that I opened ports for Jupyter Notebook and other data science tools, but I didn’t actually show how to install any of those tools.
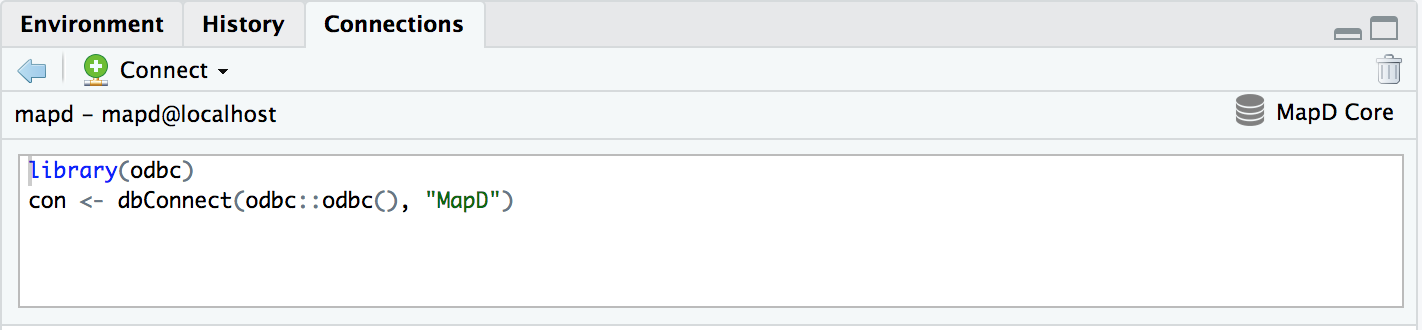
For this post, I’ll cover how to install MapD ODBC drivers and create a connection within RStudio server.
1. Installing RStudio Server on Microsoft Azure
With an Ubuntu VM running MapD, installing RStudio Server takes but a handful of commands. The RStudio Server download/install page has fantastic instructions, but if you are looking for Azure-specific RStudio Server install instructions, this blog post from Jumping Rivers does a great job.
2. Installing an ODBC Driver Manager
There are two major ODBC driver managers for Linux and macOS: unixODBC and iODBC. I have had more overall ODBC driver installation success with unixODBC than iODBC; here are the instructions for building unixODBC from source:
#download source and extract
wget ftp://ftp.unixodbc.org/pub/unixODBC/unixODBC-2.3.7.tar.gz
gunzip unixODBC*.tar.gz
tar xvf unixODBC*.tar
#compile and install
cd unixODBC-2.3.7
./configure
make
sudo make installIf you want to check everything is installed correctly, you can run the following command:
odbc_config --cflags
#result
-DHAVE_UNISTD_H -DHAVE_PWD_H -DHAVE_SYS_TYPES_H -DHAVE_LONG_LONG -DSIZEOF_LONG_INT=8 -I/usr/local/include3. Installing MapD ODBC Driver System-wide
With unixODBC installed, the next step is to install the MapD ODBC drivers. ODBC drivers for MapD are provided as part of MapD Enterprise Edition, so you’ll need to contact your sales representative to get the appropriate version for your MapD installation.
For Linux, the MapD ODBC drivers are provided as a tarball, which when extracted provides all of the necessary ODBC driver files:
#make a directory to extract files into
mkdir mapd_odbc && cd mapd_odbc
tar -xvf ../mapd_odbc_installer_linux_3.80.1.36.tar.gz
#move to /opt/mapd/mapd_odbc (or wherever the other MapD files are)
cd .. && mv mapd_odbc /opt/mapd/mapd_odbcBy convention, MapD suggests placing the ODBC drivers in the same directory as your installation (frequently, /opt/mapd). Wherever you choose to place the directory, you need add that location into the /etc/odbcinst.ini file:
[MapD Driver]
Driver = /opt/mapd/mapd_odbc/libs/libODBC.soAt this point, we have everything we need to define a connection string within R using odbc:
library(odbc)
conn <- dbConnect(odbc::odbc(),
Driver = "MapD Driver",
Server = "localhost",
Database = "mapd",
UID = "mapd",
PWD = "helloRusers!",
Port = 9091)Depending on your use case/security preferences, there are two downsides to this method: 1) the credentials are in plain-text in the middle of the script and 2) the RStudio Connection window also shows the credentials in connection window in plain-text until you delete the connection. This can be remedied by defining a DSN (data source name).
4. Defining A DSN
A DSN is what people usually think of when installing ODBC drivers, as it holds some/all of the actual details for connecting to the database. DSN files can be placed in two locations: system-wide in /etc/obdc.ini or in an individual user’s home directory (needs to be ~/.odbc.ini, a hidden file).
In order to have the credentials completely masked in the RStudio session, place the following in the /etc/obdc.ini file:
[MapD Production]
Driver=MapD Driver
PWD=helloRusers!
UID=mapd
HOST=localhost
DATABASE=mapd
PORT=9091Within the RStudio Connection pane, we can now test our DSN:
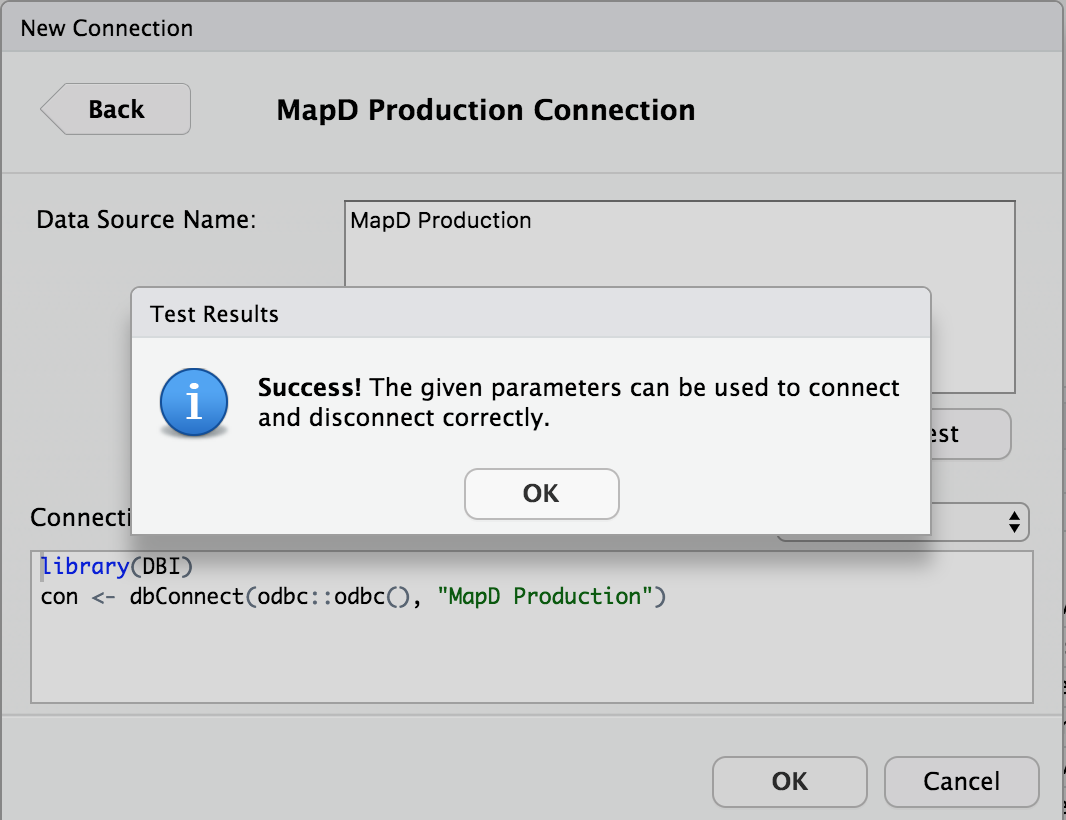
With the DSN defined, the R connection code becomes much shorter, with no credentials exposed within the R session:
library(DBI)
con <- dbConnect(odbc::odbc(), "MapD Production")ODBC: A Big Bag Of Hurt, But Super Useful
While the instructions above aren’t the easiest to work through, once you have ODBC set up and working one time, it’s usually just a matter of appending various credentials to the existing files to add databases.
From a MapD perspective, ODBC is supported through our Enterprise Edition, but it is the slowest way to work with the database. Up to this point, we’ve focused mostly on supporting Python through the pymapd package and the MapD Ibis backend, but there’s no reason technical reason why R can’t also be a first-class citizen.
So if you’re interested in helping develop an R package for MapD, whether using reticulate to wrap pymapd or to help develop Apache Thrift bindings and Apache Arrow native code, send me a Twitter message or connect via LinkedIn (or any other way to contact me) and we’ll figure out how to collaborate!