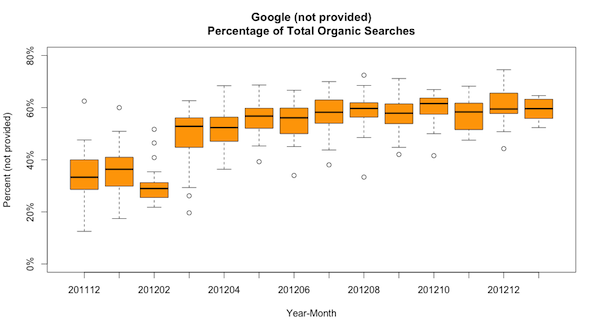
(not provided) terms from Google average 35%-60% of all Google organic search terms
For power users of Google Analytics, there is a heavy dose of spreadsheet work that accompanies any decent analysis. But even with Excel in tow, it’s often difficult to get the data just right without resorting to formula hacks and manual table formatting. This is where the Google Analytics API and R can come very much in handy.
Connecting to the Google Analytics API using R
I’m not going to say that connecting to the Google Analytics API is easy per se, but with the rga package written by “skardhamar” on GitHub, it’s easier than if you had to develop the connection code yourself! However, before you can get started making calls to the Google Analytics API, you need to register within the Google Analytics API console. There you can define a new project and then you’ll be able to make your API calls via R.
After you have your API access straightened out, the GitHub page for the rga package has all the details in how to authenticate using the rga.open function. I chose to use the where argument so that I can continuously hit the API across many sessions without having to do browser authentication each time.
1
rga.open(instance = "ga", where = "~/Documents/R/ga-api")
Analyzing (not provided) as a Google Analytics organic search term
Once connected to the Google Analytics API, now it’s time to submit our API calls. I used two API calls to create the graph at the top of the post, which shows the percentage of all Google organic search terms that are listed as “(not provided)” for the entire history of this blog. The two API calls were to download the number of total organic search term visits by date from Google and the number of “(not provided)” visits by date, also from Google. Here’s the API call for the “(not provided)” data (replace XXXXXXXX with your profile ID):
1
2
3
4
5
6
7
8
visits_notprovided.df <- ga$getData(XXXXXXXX,
start.date = "2011-01-01",
end.date = "2013-01-10",
metrics = "ga:visits",
filters = "ga:keyword==(not provided);ga:source==google;ga:medium==organic",
dimensions = "ga:date",
max = 1500,
sort = "ga:date")
The result of this API call provides an R data frame containing two columns: date and number of visits where the search term was “(not provided)”.
Munging the data using R
After pulling the data into R, all that’s left is to merge the data frames, do a few calculations, then make the boxplot. Because the default object returned by the rga package is a data frame, it’s trivial to use the merge function in R to join the data frames, then use a few calculated columns to create the percentage of visits that are “(not provided)”
What was that Google, only 10% of searches are supposed to be (not provided)?
By now, it’s beating a dead horse that the percentage of “(not provided)” search results from Google FAR exceeds what they said it would. This blog gets about 5,000 visits a month, and due to the technical nature of the blog many of the users are using Chrome (which does secure search automatically) or from iOS (which also does secure search). But at minimum, this graph illustrates the power of using the Google Analytics API via R; I can update this graph at my leisure by running my script, and I can create a graphic that’s not possible within Excel.
Full code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
#### Connecting to Google Analytics API via R
#### Uses OAuth 2.0
#### https://developers.google.com/analytics/devguides/reporting/core/v3/ for documentation
# Install devtools package & rga - This is only done one time
install.packages("devtools")
library(devtools)
install_github("rga", "skardhamar")
# Load rga package - requires bitops, RCurl, rjson
# Load lubridate to handle dates
library(rga)
library(lubridate)
# Authenticating to GA API. Go to https://code.google.com/apis/console/ and create
# an API application. Don't need to worry about the client id and shared secret for
# this R code, it is not needed
# If file listed in "where" location doesn't exist, browser window will open.
# Allow access, copy code into R console where prompted
# Once file located in "where" directory created, you will have continous access to
# API without needing to do browser authentication
rga.open(instance = "ga", where = "~/Documents/R/ga-api")
# Get (not provided) Search results. Replace XXXXXXXX with your profile ID from GA
visits_notprovided.df <- ga$getData(XXXXXXXX,
start.date = "2011-01-01",
end.date = "2013-01-10",
metrics = "ga:visits",
filters = "ga:keyword==(not provided);ga:source==google;ga:medium==organic",
dimensions = "ga:date",
max = 1500,
sort = "ga:date")
names(visits_notprovided.df)<- c("hit_date", "np_visits")
# Get sum of all Google Organic Search results. Replace XXXXXXXX with your profile ID from GA
visits_orgsearch.df <- ga$getData(XXXXXXXX,
start.date = "2011-01-01",
end.date = "2013-01-10",
metrics = "ga:visits",
filters = "ga:source==google;ga:medium==organic",
dimensions = "ga:date",
max = 1500,
sort = "ga:date")
names(visits_orgsearch.df)<- c("hit_date", "total_visits")
# Merge files, create metrics, limit dataset to just days when tags firing
merged.df <- merge(visits_notprovided.df, visits_orgsearch.df, all=TRUE)
merged.df$search_term_provided <- merged.df$total_visits - merged.df$np_visits
merged.df$pct_np <- merged.df$np_visits / merged.df$total_visits
merged.df$yearmo <- year(merged.df$hit_date)*100 + month(merged.df$hit_date)
final_dataset = subset(merged.df, total_visits > 0)
# Visualization - boxplot by month
# Main plot, minus y axis tick labels
boxplot(pct_np~yearmo,data=final_dataset, main="Google (not provided)\nPercentage of Total Organic Searches",
xlab="Year-Month", ylab="Percent (not provided)", col= "orange", ylim=c(0,.8), yaxt="n")
#Create tick sequence and format axis labels
ticks <- seq(0, .8, .2)
label_ticks <- sprintf("%1.f%%", 100*ticks)
axis(2, at=ticks, labels=label_ticks)