It’s hard to believe it’s been over 2.5 years since I wrote about my experience with Apple trying to get my Broken MacBook Pro Hinge fixed. Since that time, my Late 2008 MacBook Pro continued to work flawlessly, most of the time keeping up with the scientific programming I would do in R, Python or Julia.
Unfortunately, it seems near impossible (if not completely impossible) to get an OEM A1281 battery as a drop-in replacement. When I went to the Apple Store at Suburban Square, PA, the “Genius” that looked at my computer took 15-20 minutes to look on the Apple website (which I obviously did before arriving, so no value-add there), only to show me a battery in stock that didn’t fit my model of computer. Only after shaming him into looking up the actual part number, was he able to utter the phrase:
Oh, no, we don’t have those any more. Your model MacBook Pro was declared “Vintage”. No more original parts are available from Apple.
Of course it is. After getting home, I was able to find this service bulletin from Apple, which outlines which models are obsolete. Apparently, it’s a hard and fast rule that once five years from the end of manufacturing arrives, a model is declared vintage (unless local laws require longer service). So even though the only “problem” with my MacBook Pro is that I was only getting one hour of battery life per charge (or less if I’m compiling code), the computer is destined for a new life somewhere else.
“Vintage” For Me, Powerful For Thee
While I realize I could go the 3rd-party route and get a replacement battery, at some point, you can only spend so much money keeping older technology alive. Since I use computers pretty intensively, I ended up getting a “new” (used) 2011 MacBook Pro from a neighborhood listing that has decent life on the OEM battery. Surprisingly, I was able to get $360 for my Late-2008 MacBook Pro, being fully honest about the condition, issues and battery life. The older woman who I sold it to fully understood, but worked at a desk and didn’t care about the battery! She also said:
This is easily the most powerful computer I’ve ever owned.
Apple, like I said in my original post, you’ve got a customer for life. And while I’ve moved on to a newer machine, it’s beyond amazing to me that a 7-year old computer will continue to live on and work at a high level of performance. And with my 2011 MacBook Pro, I still have the option to upgrade the parts (though I don’t need to…SSD, 16GB of RAM and a quad-core i7 processor already!)
The Retina MacBook’s are nice, but very incremental. Here’s hoping the 2011 MacBook Pro lasts as long as my Late 2008 MacBook Pro did!
As I’ve become more serious about contributing in the open-source community, having quality tests for my packages has been something I’ve spent much more time on than when I was just writing quick-and-dirty code for my own purposes. My most used open-sourced package is RSiteCatalyst, which accesses the Adobe Analytics (authenticated) API, which poses a problem: how do you maintain a project on GitHub with a full test suite, while at the same time not hard-coding your credentials in plain sight for everyone to see?
In terms of a testing framework, Hadley Wickham provides a great testing framework in testthat; while I wouldn’t go as far as he does to say that the package makes testing fun, it certainly makes testing easy. Let’s take a look at some of the tests in RSiteCatalyst from the QueueOvertime function:
test_that("Validate QueueOvertime using legacy credentials",{skip_on_cran()#Correct [masked] credentialsSCAuth(Sys.getenv("USER",""),Sys.getenv("SECRET",""))#Single Metric, No granularity (summary report)aa<-QueueOvertime("zwitchdev","2014-01-01","2014-12-31","visits","")#Validate returned value is a data.frameexpect_is(aa,"data.frame")#Single Metric, Daily Granularitybb<-QueueOvertime("zwitchdev","2014-01-01","2014-12-31","visits","day")#Validate returned value is a data.frameexpect_is(bb,"data.frame")#Single Metric, Week Granularitycc<-QueueOvertime("zwitchdev","2014-01-01","2014-12-31","visits","week")#Validate returned value is a data.frameexpect_is(cc,"data.frame")#Two Metrics, Week Granularitydd<-QueueOvertime("zwitchdev","2014-01-01","2014-12-31",c("visits","pageviews"),"week")#Validate returned value is a data.frameexpect_is(dd,"data.frame")#Two Metrics, Month Granularity, Social Visitorsee<-QueueOvertime("zwitchdev","2014-01-01","2014-12-31",c("visits","pageviews"),"month","5433e4e6e4b02df70be4ac63")#Validate returned value is a data.frameexpect_is(ee,"data.frame")#Two Metrics, Day Granularity, Social Visitors, Anomaly Detectionff<-QueueOvertime("zwitchdev","2014-01-01","2014-12-31",c("visits","pageviews"),"day","5433e4e6e4b02df70be4ac63",anomaly.detection="1")#Validate returned value is a data.frameexpect_is(ff,"data.frame")})
From the code above, you can see the tests are fairly simplistic; for a given number of permutations of arguments of the function, I test to see if a data frame was returned. This is because, for the most part, RSiteCatalyst is just a means of generating JSON calls, submitting them to the Adobe Analytics API, then parsing the results into an R data frame.
Since there is very little additional logic in the package, I don’t spend a bunch of time testing what data is actually returned (i.e. what is returned depends on the Adobe Analytics API, not R). What is interesting is line 6; I reference Sys.getenv() twice in order to pass in my username and key for the Adobe Analytics API, which feels very “interactive R”, but the goal is automated testing. Filling in those two environment variables is where Travis CI comes in.
Travis CI Configuration
In order to have any automation using Travis CI, you need to create a .travis.yml configuration file. While you can read the Travis docs to create the .travis.yml file for R, you’re probably better off just using the use_travis function from devtools (also from Hadley, little surprise!) to create the file for you. In terms of creating encrypted keys to use with Travis, you’ll need to use the Travis CLI tool, which is distributed as a Ruby gem (i.e. package). If you view the RSiteCatalyst .travis.yml file, you can see that I define two global “secure” variables, the value of which are the output from running a command similar to the following in the Travis CLI tool:
$ travis encrypt RANDY=ZWITCH
Please add the following to your .travis.yml file:
secure: "b6S4dBc7arvox8UpuFqkz+VP2UmAW/S/B/vgaAdZiZQqUp78YDR6VYdAYN3WisCK1VLGjOVVPQvGxLik0pQokF8FU3sjX0ekH6vSJeqg4utrEZmVtNvdDLEVAmagFy8Fyduow3U4CPW7rzXqvAE4cIVqGR5Lv2KLf8ANUGn+y3E="
Pro Tip: You can add it automatically by running with --add.
Note that if this seems insecure, every time you run the encrypt command with the same arguments, you get a different value; Travis CI is creating new public and private RSA keys each time.
Setting Up Authenticated Testing Locally
If you get as far as setting up encrypted Travis CI keys and tests using testthat, the final step is really for convenience. With the .travis.yml file, Travis CI sets the R environment variables on THEIR system; on your local machine, the environment variables aren’t set. Even if the environment variables were set, they would be set to the Travis CI hashed values, which is not what I want to pass to my authentication function in my R package.
To set the authentication variables locally, so that each time you hit ‘check’ to build and check against CRAN errors, you just need to modify the .Renviron file for R:
USER="myusername"SECRET="mysecret"
With that minor change, in addition to the .travis.yml file, you’ll have a seamless environment for developing and testing R packages.
Testing Is Like Flossing…
As easy as the testthat and devtools packages make testing, and as inexpensively as Travis CI is as a service (free for open source projects!), there’s really no excuse to provide packaged-up code and not include tests. Hopefully this blog post has demonstrated that it’s possible to include tests even when authentication is necessary without compromising your credentials.
So let’s all be sure to include tests, not just pay lip service to the idea that testing is useful. Code testing only works if you actually do it 🙂
“Well, first you need a TMS and a three-tiered data layer, then some jQuery with a node backend to inject customer data into the page asynchronously if you want to avoid cookie-based limitations with cross-domain tracking and be Internet Explorer 4 compatible…”
Blah Blah Blah. There’s a whole cottage industry around jargon-ing each other to death about digital data collection. But why? Why do we focus on tools, instead of the data? Because the tools are necessarily inflexible, so we work backwards from the pre-defined reports we have to the data needed to populate them correctly. Let’s go the other way for once: clickstream data to analysis & reporting.
In this blog post, I will show the structure of the Adobe Analytics Clickstream Data Feed and how to work with a day worth of data within R. Clickstream data isn’t as raw as pure server logs, but the only limit to what we can calculate from clickstream data is what we can accomplish with a bit of programming and imagination. In later posts, I’ll show how to store a year worth of data in a relational database, storing the same data in Hadoop and doing analysis using modern tools such as Apache Spark.
This blog post will not cover the mechanics of getting the feed delivered via FTP. The Adobe Clickstream Feed documentation is sufficiently clear in how to get started.
FTP/File Structure
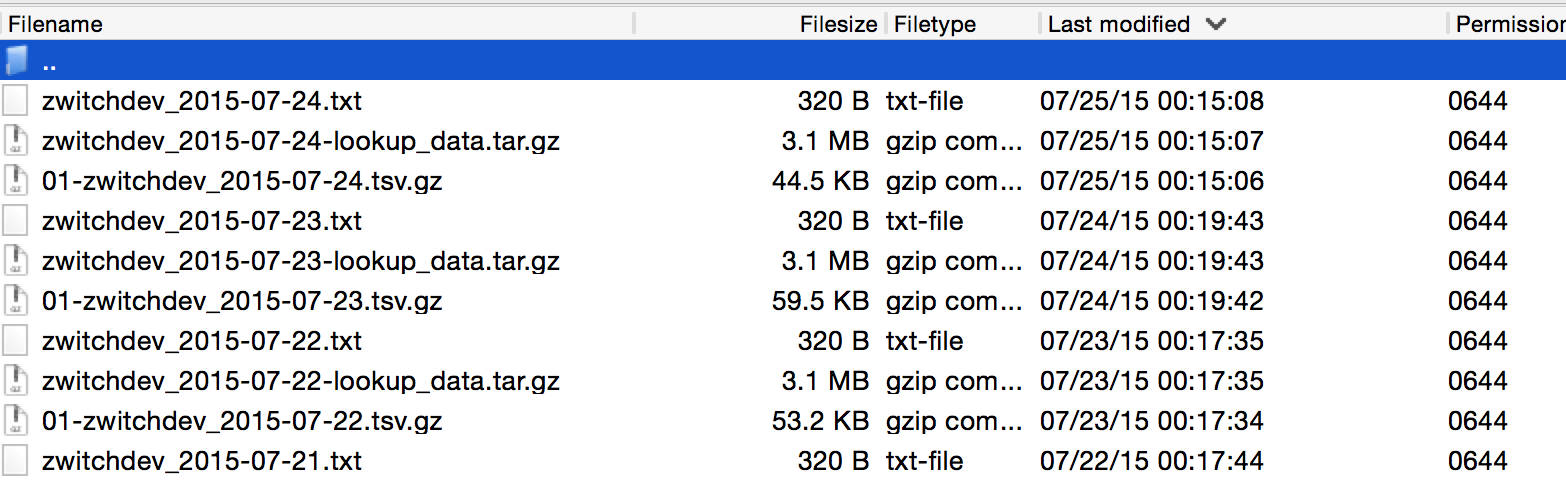
Once your Adobe Clickstream Feed starts being delivered via FTP, you’ll have a file listing that looks similar to the following:
What you’ll notice is that with daily delivery, three files are provided, each having a consistent file naming format:
\d+-\S+_\d+-\d+-\d+.tsv.gz
This is the main file containing the server call level data
\S+_\d+-\d+-\d+-lookup_data.tar.gz
These are the lookup tables, header files, etc.
\S+_\d+-\d+-\d+.txt
Manifest file, delivered last so that any automated processes know that Adobe is finished transferring
The regular expressions will be unnecessary for working with our single day of data, but it’s good to realize that there is a consistent naming structure.
Checking md5 hashes
As part of the manifest file, Adobe provides md5 hashes of the files. There are at least two purposes to this, including 1) making sure that the files truly were delivered in full and 2) that the files haven’t been manipulated/tampered with. In order to check that your md5 hashes match the values provided by Adobe, we can do the following in R:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
setwd("~/Downloads/datafeed/")#Read in Adobe manifest filemanifest<-read.table("zwitchdev_2015-07-13.txt",stringsAsFactors=FALSE)names(manifest)<-c("key","value")#Use digest library to calculate md5 hasheslibrary(digest)servercalls_md5<-digest("01-zwitchdev_2015-07-13.tsv.gz",algo="md5",file=TRUE)lookup_md5<-digest("zwitchdev_2015-07-13-lookup_data.tar.gz",algo="md5",file=TRUE)#Check to see if hashes contained in manifest fileservercalls_md5%in%manifest$value#[1] TRUElookup_md5%in%manifest$value#[1] TRUE
As we can see, both calculated hashes are contained within the manifest, so we can be confident that the files we downloaded haven’t been modified.
Unzipping and Loading Raw Files to Data Frames
Now that our file hashes are validated, it’s time to load the files into R. For the example files, I would be able to fit the entire day into RAM because my blog does very little traffic. However, I’m going to still limit the rows brought in, as if we were working with a large e-commerce website with millions of visits per day:
#Get list of lookup files from tarballfiles_tar<-untar("zwitchdev_2015-07-13-lookup_data.tar.gz",list=TRUE)#Extract files to _temp directory. Directory will be created if it doesn't existuntar("zwitchdev_2015-07-13-lookup_data.tar.gz",exdir="_temp")#Read each file into a data frame#If coding like this in R offends you, keep it to yourself...for(fileinfiles_tar){df_name<-unlist(strsplit(file,split=".tsv",fixed=TRUE))temp_df<-read.delim(paste("_temp",file,sep="/"),header=FALSE,stringsAsFactors=FALSE)#column_headers not used as lookup tableif(df_name!="column_headers"){names(temp_df)<-c("id",df_name)}assign(df_name,temp_df)rm(temp_df)}#gz files can be read directly into dataframes from base R#Could also use `readr` library for performanceservercall_data<-read.delim("~/Downloads/datafeed/01-zwitchdev_2015-07-13.tsv.gz",header=FALSE,stringsAsFactors=FALSE,nrows=500)#Use column_headers to label servercall_data data frame using first row of datanames(servercall_data)<-column_headers[1,]
If we were to be loading this data into a database, we’d be done with our processing; we have all of our data read into R and it would be a trivial exercise to load the data into a database (we’ll do this in a separate blog post). But since we’re going to be analyze this single day of clickstream data, we need to join these 14 data frames together.
SQL: The Most Important Language for Analytics
As a slight tangent, if you don’t know SQL, then you’re going to have a really hard time doing any sort of advanced analytics. There are literally millions of tutorials on the Internet (including this one from me), and understanding how to join and retrieve data from databases is the key to being more than just a report monkey.
The reason why the prior code creates 14 data frames is because the data is delivered in a normalized structure from Adobe. Now we are going to de-normalize the data, which is just a fancy way of saying “join the files together in order to make a gigantic table.”
There are probably a dozen different ways to join data frames using just R code, but I’m going to do it using the sqldf package so that I can use SQL. This will allow for a single, declarative statement that shows the relationship between the lookup and fact tables:
library(sqldf)query<-"select
sc.*,
browser.browser as browser_name,
browser_type,
connection_type.connection_type as connection_name,
country.country as country_name,
javascript_version,
languages.languages as languages,
operating_systems,
referrer_type,
resolution.resolution as screen_resolution,
search_engines
from servercall_data as sc
left join browser on sc.browser = browser.id
left join browser_type on sc.browser = browser_type.id
left join connection_type on sc.connection_type = connection_type.id
left join country on sc.country = country.id
left join javascript_version on sc.javascript = javascript_version.id
left join languages on sc.language = languages.id
left join operating_systems on sc.os = operating_systems.id
left join referrer_type on sc.ref_type = referrer_type.id
left join resolution on sc.resolution = resolution.id
left join search_engines on sc.post_search_engine = search_engines.id
;
"denormalized_df<-sqldf(query)
There are three lookup tables that weren’t used: color_depth, plugins and event. The first two don’t have a lookup column in my data feed (click link for a full listing of Adobe Clickstream data feed columns available). These columns aren’t really useful for my purposes anyway, so not a huge loss. The third table, the event list, requires a separate processing step.
Processing Event Data
As normalized as the Adobe Clickstream Data Feed is, there is one oddity: the events per server call come in a comma-delimited string in a single column with a lookup table. This implies that a separate level of processing is necessary, outside of SQL, since the column “key” is actually multiple keys and the lookup table specifies one event type per row. So if you were to try and join the data together, you wouldn’t get any matches.
To deal with this in R, we are going to do an EXTREMELY wasteful operation: we are going to create a data frame with a column for each possible event, then evaluate each row to see if that event occurred. This will use a massive amount of RAM, but of course, this is a feature/limitation of R which wouldn’t be an issue if the data were stored in a database.
#Create friendly names in events table replacing spaces with underscoresevent$names_filled<-tolower(gsub(" ","_",event$event))#Initialize a data frame with all 0 values#Dimensions are number of observations as rows, with a column for every possible eventevent_df<-data.frame(matrix(data=0,ncol=nrow(event),nrow=nrow(servercall_data)))names(event_df)<-event$id#Parse comma-delimited string into vector#Each vector value represents column name in event_df, assign value of 1for(rowinservercall_data$post_event_list){if(!is.na(row)){for(event_instrsplit(row,",")){event_df[as.character(event_)]<-1}}}#Rename columns with "friendly" namesnames(event_df)<-event$names_filled#Horizontally join datasets to create final datasetoneday_df<-cbind(denormalized_df,event_df)
With the final cbind command, we’ve created a 500 row x 1562 column dataset representing a sample of rows from one day of the Adobe Clickstream Data Feed. Having the data denormalized in this fashion takes 6.13 MB of RAM…extrapolating to 1 million rows, you would need 12.26GB of RAM (per day of data you want to analyze, if stored solely in memory).
Next Step: Analytics?!
A thousand words in and 91 lines of R code and we still haven’t done any actual analytics. But we’ve completed the first step in any analytics project: data prep!
In future blog posts in this series, I’ll demonstrate how to actually use this data in analytics, from re-creating reports available in the Adobe Analytics UI (to prove the data is the same) to more advanced analysis such as using association rules, which can be one method for creating a “You may also like…” functionality such as the one at the bottom of this blog.