For being in RSiteCatalyst retirement, I’m ending up working on more functionality lately ¯_(ツ)_/¯. Here are the changes for RSiteCatalyst 1.4.8, which should be available on CRAN shortly:
Segment Stacking
RSiteCatalyst now has the ability to take multiple values in the segment.id keyword for the Queue* functions. This functionality was graciously provided by Adam Gitzes, closing an issue that was nearly a year old. At times it felt like I was hazing him with change requests, but for Adam’s first open-source contribution, this is a huge addition in functionality.
So now you are able to pass multiple segments into a function call and get an ‘AND’ behavior like so:
The result (Visits from Social AND Visits from Apple Browsers):
QueueSummary: Now with date.to and date.from keywords
In response to GitHub issue #158, date.to and date.from parameters were added; this was a minor, but long-term oversight (it’s always been possible to do this in the Adobe Analytics API). So now rather than just specifying the date keyword and getting a full-year summary or a full-month, you can specify any arbitrary start/end dates.
Starting with the newest version of httr, you get a message for any API call where the encoding wasn’t set. So for long running Queue* requests, you may have received dozens of warnings to stdout about "No encoding supplied: defaulting to UTF-8." This has been remedied, and the warning should no longer occur.
Also, the documentation for the Queue* functions was clarified to show an example of using SAINT classifications as the report breakdown; hopefully this didn’t cause too much confusion to anyone else.
Volunteers Wanted!
As I referenced in the first paragraph, while I’m fully committed to maintaining RSiteCatalyst, I don’t currently have the time/desire to continue to develop the package to improve functionality. Given that I don’t use this package for my daily work, it’s hard for me to dedicate time to the project.
Thanks again to Adam Gitzes who stepped up and provided significant effort to close an outstanding feature request. I would love if others in the digital analytics community would follow Adam’s lead; don’t worry about whether you are ‘good enough’, get a working solution together and we’ll figure out how to harden the code and get it merged. Be the code change you want to see the world 🙂
In my previous post about the Adobe Analytics Clickstream Data Feed, I showed how it was possible to take a single day worth of data and build a dataframe in R. However, most likely your analysis will require using multiple days/weeks/months of data, and given the size and complexity of the feed, loading the files into a relational database makes a lot of sense.
Although there may be database-specific “fast-load” tools more appropriate for this application, this blog post will show how to handle this process using only R and PostgresSQL.
File Organization
Before getting into the loading of the data into PostgreSQL, I like to sort my files by type into separate directories (remember from the previous post, you’ll receive three files per day). R makes OS-level operations simple enough:
#### 1. Setting directory to FTP folder where files incoming from Adobe## Has ~2000 files in it from 2 years of datasetwd("~/Downloads/datafeed/")#### 2. Sort files into three separate folders## Manifests - plain text filesif(!dir.exists("manifest")){dir.create("manifest")lapply(list.files(pattern="*.txt"),function(x)file.rename(x,paste("manifest",x,sep="/")))}## Server calls tsv.gzif(!dir.exists("servercalls")){dir.create("servercalls")lapply(list.files(pattern="*.tsv.gz"),function(x)file.rename(x,paste("servercalls",x,sep="/")))}## Lookup files .tar.gzif(!dir.exists("lookup")){dir.create("lookup")lapply(list.files(pattern="*.tar.gz"),function(x)file.rename(x,paste("lookup",x,sep="/")))}
Were there more file types, I could’ve abstracted this into a function instead of copying the code three times, but the idea is the same: Check to see if the directory exists, if it doesn’t then create it and move the files into the directory.
Connecting and Loading Data to PostgreSQL from R
Once we have our files organized, we can begin the process of loading the files into PostgreSQL using the RPostgreSQL R package. RPostgreSQL is DBI-compliant, so the connection string is the same for any other type of database engine; the biggest caveat of loading your servercall data into a database is the first load is almost guaranteed to require loading as text (using colClasses = "character" argument in R). The reason that you’ll need to load the data as text is that Adobe Analytics implementations necessarily change over time; text is the only column format that allows for no loss of data (we can fix the schema later within Postgres either by using ALTER TABLE or by writing a view).
library(RPostgreSQL)# Connect to databaseconn=dbConnect(dbDriver("PostgreSQL"),user="postgres",password="",host="localhost",port=5432,dbname="adobe")#Set directory to avoid having to use paste to build urlssetwd("~/Downloads/datafeed/servercalls")#Set column headers for server callscolumn_headers<-read.delim("~/Downloads/datafeed/lookup/column_headers.tsv",stringsAsFactors=FALSE)#Loop over entire list of files#Setting colClasses to character only way to guarantee all data loads#File formats or implementations can change over time; fix schema in database after data loadedfor(fileinlist.files()){print(file)df<-read.csv2(file,sep="\t",header=FALSE,stringsAsFactors=FALSE,colClasses="character")dbWriteTable(conn,name='servercalls',value=df,row.names=FALSE,append=TRUE)rm(df)}#Run analyze in PostgreSQL so that query planner has accurate informationdbGetQuery(conn,"analyze servercalls")
With this small amount of code, we’ve generated the table definition structure (see here for the underlying Postgres code), loaded the data, and told Postgres to analyze the table to gather statistics for efficient queries. Sweet, two years of data loaded with minimal effort!
Loading Lookup Tables Into PostgreSQL
With the server call data loaded into our database, we now need to load our lookup tables. Lucky for us, these do maintain a constant format, so we don’t need to worry about setting all the fields to text, RPostgreSQL should get the column types correct.
library(RPostgreSQL)# Connect to databaseconn=dbConnect(dbDriver("PostgreSQL"),user="postgres",password="",host="localhost",port=5432,dbname="adobe")setwd("~/Downloads/datafeed/lookup/")#Create function due to repetitiveness#Since we're loading lookup tables with mostly same values each time, put source file in tableloadlookup<-function(tblname){df<-read.csv2(paste(tblname,".tsv",sep=""),sep="\t",header=FALSE,stringsAsFactors=FALSE)df$file<-filedbWriteTable(conn,name=tblname,value=df,row.names=FALSE,append=TRUE)}#untar files, place in directory by dayfor(fileinlist.files(pattern="*.tar.gz")){print(file)untar(file)for(tblinc("browser_type","browser","color_depth","column_headers","connection_type","country","event","javascript_version","languages","operating_systems","plugins","referrer_type","resolution","search_engines")){loadlookup(tbl)}}
SHORTCUT: The dimension tables that are common to all report suites don’t really change over time, although that isn’t guaranteed. In the 758 days of files I loaded (code), the only files having more than one value for a given key were: browser, browser_type, operating_system, search_engines, event (report suite specific for every company) and column_headers (report suite specific for every company). So if you’re doing a bulk load of data, it’s generally sufficient to use the newest lookup table and save yourself some time. If you are processing the data every day, you can use an upsert process and generally there will be few if any updates.
Let’s Do Analytics!!!!???!!!
Why is there always so much ETL work, I want to data science the hell out of some data
At this point, if you were uploading the same amount of data for the traffic my blog does (not much), you’d be about 1-2 hours into loading data, still having done no analysis. In fact, in order to do analysis, you’d still need to modify the column names and types in your servercalls table, update the lookup tables to have the proper column names, and maybe you’d even want to pre-summarize the tables into views/materialized views for Page View/Visit/Visitor level. Whew, that’s a lot of work just to calculate daily page views.
Yes it is. But taking on a project like this isn’t for page views; just use the Adobe Analytics UI!
In a future blog post or two, I’ll demonstrate how to use this relational database layout to perform analyses not possible within the Adobe Analytics interface, and also show how we can skip this ETL process altogether using a schema-on-read process with Spark.
This will be a very short post, because the only “new” information I’m going to provide is the minimal example to answer the question. Yes, it is in fact possible to call RSiteCatalyst from Python and seems to work well. The most important things are 1) making sure you install rpy2 and 2) loading Pandas (since so much of RSiteCatalyst is API calls returning data frames). It doesn’t hurt to already have experience using RSiteCatalyst in R, since all we’re doing here is using Python to pass code to R.
Setup Code: rpy2 and Pandas
To call an R package from Python, the rpy2 package works very well, both from the REPL and Jupyter Notebook. For RSiteCatalyst, here is the set up code:
1
2
3
4
5
6
7
8
9
10
importpandasaspdimportrpy2.robjects.packagesasrpackagesfromrpy2.robjectsimportpandas2ri# Activate ability to translate R objects to pandas data frames
pandas2ri.activate()# Load RSiteCatalyst into Python
rsc=rpackages.importr('RSiteCatalyst')
With this code run, now you can make calls to the RSiteCatalyst R package, just as if you were in R itself.
Sample Call: GetReportSuites
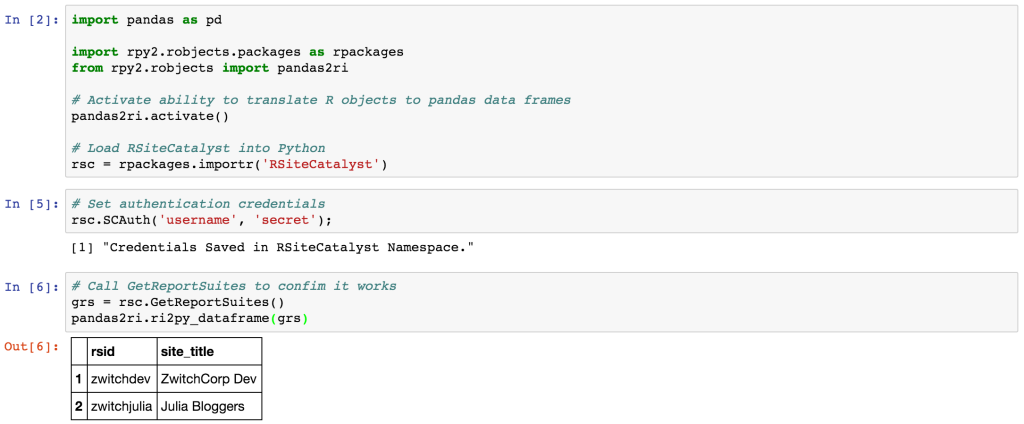
Just to prove it works, here’s a code snippet using GetReportSuites():
1
2
3
# Call GetReportSuites to confim it works
grs=rsc.GetReportSuites()pandas2ri.ri2py_dataframe(grs)
And in Jupyter Notebook, you would see something similar to:
But, Why?
So that’s about it…if you wanted to, you could call RSiteCatalyst from Python without much effort. There aren’t a whole lot of reasons to do so, unless like Adam above, you’d rather just use Python. I suppose if you wanted to use some other Python packages, such as Flask to create a dashboard or Seaborn for visualization you might want to do this. Until I got this tweet, it never occurred to me to do this, so YMMV.
Edit, 2/26/16: Adam Gitzes, who originally asked the question, also provides a different solution using Jupyter Notebook magics at his blog post here