Over the past month or so, I’ve been playing with a new scientific programming language called ‘Julia’, which aims to be a high-level language with performance approaching that of C. With that goal in mind, Julia could be a replacement for the ‘multi-language’ problem of needing to move between R, Python, MATLAB, C, Fortran, Scala, etc. within a single scientific programming project. Here are some observations that might be helpful for others looking to get started with Julia.
Get used to ‘Git’ and ‘make’
While there are pre-built binaries for Julia, due to the rapid pace of development, it’s best to build Julia from source. To be able to keep up with the literally dozen code changes per day, you can clone the Julia GitHub repository to your local machine. If you use one of the GitHub GUI’s, this is as easy as hitting the ‘Sync Branch’ button to receive all of the newest code updates.
To install Julia, you need to compile the code. The instructions for each supported operating system are listed on the Julia GitHub page. For Mac users, use Terminal to navigate to the directory where you cloned Julia, then run the following command, where ‘n’ refers to the number of concurrent processes you want the compiler to use:
1
make-jn
I use 8 concurrent processes on a 2013 MacBook Pro and it works pretty well. Certainly much faster than a single process. Note that the first time you run the make command, the build process will take much longer than successive builds, as Julia downloads all the required libraries needed. After the first build, you can just run the make command with a single process, as the code updates don’t take very long to build.
Package management is also done via GitHub. To add Julia packages to your install, you use the Pkg.add() function, with the package name in double-quotes.
Julia code feels very familiar
Text file import
Although the Julia documentation makes numerous references to MATLAB in terms of code similarity, Julia feels very familiar to me as an R and Python user. Take reading a .csv file into a dataframe and finding the dimensions of the resulting object
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#R: Read in 1987.csv from airline dataset into a dataframe#No import statement needed to create a dataframe in Rairline1987<-read.csv("~/airline/1987.csv")dim(airline1987)[1]131182629#Python: use pandas to create a dataframeimportpandasaspdairline1987=pd.read_csv("/Users/randyzwitch/airline/1987.csv")airline1987.shapeOut[7]:(1311826,29)#Julia: use DataFrames to create a dataframeusingDataFramesairline1987=readtable("/Users/randyzwitch/airline/1987.csv")size(airline1987)(1311826,29)
In each language, the basic syntax is to call a ‘read’ function, specify the .csv filename, then the defaults of the function read in a basic file. I also could’ve specified other keyword arguments, but for purposes of this example I kept it simple.
Looping
Looping in Julia is similar to other languages. Python requires proper spacing for each level of a loop, with a colon for each evaluated expression. And although you generally don’t use many loops in R, to do so requires using parenthesis and brackets.
#Python looping to create a term-frequency dictionaryfromcollectionsimportCounterterm_freq=Counter()forwordinenglish_dictionary:forurlinurl_list:ifwordinurl_list:term_freq[word]+=1#Julia looping to create a term-frequency dictionaryterm_freq=Dict{String,Int64}()forwordinenglish_dictionaryforurlinurl_listifsearch(line,word)!=(0:-1)term_freq[word]=get(term_freq,word,0)+1endendend
If you’re coming from a Python background, you can see that there’s not a ton of difference between Python looping into a dictionary vs. Julia. The biggest differences are the use of the end control-flow word and that Julia doesn’t currently have the convenience “Counter” object type. R doesn’t natively have a dictionary type, but you can add a similar concept using the hash package.
#Cube every number from 1 to 100#Python map functioncubes=map(lambda(x):x*x*x,range(1,100))#Python list comprehensioncubes=[x*x*xforxinrange(1,100)]#R sapply functioncubes<-sapply(seq(1,100),function(x)x*x*x)#Julia map functioncubes=map((x)->x*x*x,[1:100])#Julia list comprehensioncubes=[x*x*xforxin[1:100]]
In each case, the syntax is just about the same to apply a function across a list/array of numbers.
A small, but intense community
One thing that’s important to note about Julia at this stage is that it’s very early. If you’re going to be messing around with Julia, there’s going to be a lot of alone-time experimenting and reading the Julia documentation. There are also several other resources including a Julia-Users Google group, Julia for R programmers, individual discussions on GitHub in the ‘Issues’ section of each Julia package, and a few tutorials floating around (here and here).
Beyond just the written examples though, I’ve found that the budding Julia community is very helpful and willing in terms of answering questions. I’ve been bugging the hell out of John Myles White and he hasn’t complained (yet!), and even when code issues are raised through the users group or on GitHub, ultimately everyone has been very respectful and eager to help. So don’t be intimidated by the fact that Julia has a very MIT and Ph.D-ness to it…jump right in and migrate some of your favorite code over from other languages.
While I haven’t moved to using Julia for my everyday workload, I am getting facility to the point where I’m starting to consider using Julia for selected projects. Once the language matures a bit more, JuliaStudio starts to approach RStudio in terms of functionality, and I get more familiar with the language in general, I can see Julia taking over for at least one if not all of my scientific programming languages.
In part 2 of the “Getting Started Using Hadoop” series, I discussed how to build a Hadoop cluster on Amazon EC2 using Cloudera CDH. This post will cover how to get your data into the Hadoop Distributed File System (HDFS) using the publicly available “Airline Dataset”. While there are multiple ways to upload data into HDFS, this post will only cover the easiest method, which is to use the Hue ‘File Browser’ interface.
Loading data into HDFS using Hue
'File Browser' in Hue (Cloudera)
Loading data into Hadoop using Hue is by far the easiest way to get started. Hue provides a GUI that provides a “File Browser” like you normally see in Windows or OSX. The workflow here would be to download each year of Airline data to your local machine, then upload each file using the Upload -> Files menu drop-down.
While downloading files from one site on the Internet, then uploading files to somewhere else on the Internet is somewhat wasteful of time and bandwidth, as a tutorial to get started with Hadoop this isn’t the worst thing in the world. For those of you who are OSX users and comfortable using Bash from the command line, here’s some code so you don’t have to babysit the download process:
1
2
3
4
5
$ for i in{1987..2008}>do> curl http://stat-computing.org/dataexpo/2009/$i.csv.bz2 >$i.csv.bz2
> bunzip2 $i.csv.bz2
>done
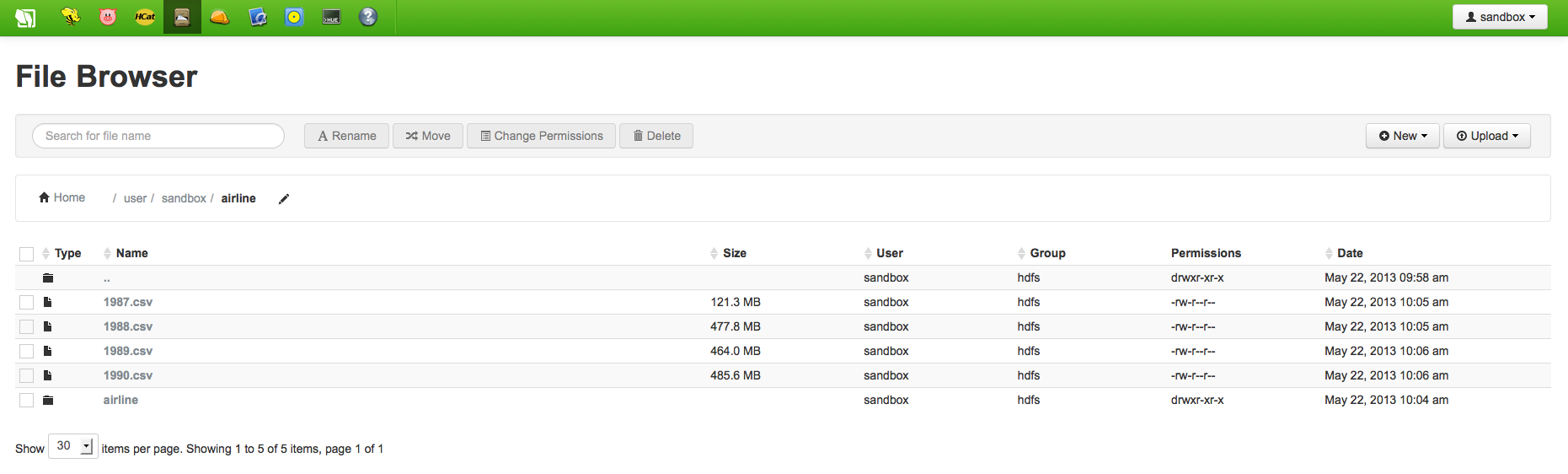
Because you are going to be uploading a bunch of text files to your Hadoop cluster, I’d recommend zipping the files prior to upload. It doesn’t matter if you use .zip or .gz files with one key distinction: if you use .zip files, you will upload using the “Zip Files” button in the File Browser; if you choose .gz, then you must use the “Files” line in the File Browser. Not only will zipping the files make the upload faster, but it will also make sure you only need to do the process once (as opposed to hitting the upload button on each file). Using the .zip file upload process, you should something like the following…a new folder with all of the files extracted automatically:
.zip file automatically extracted into folder with files (Hortonworks)
Next Steps
With the airline .csv files loaded for each year, we can use Pig or Hive to load the tables into a master dataset & schema. That will be the topic of the next tutorial.
Recently, I’ve been getting my blood pressure up reading (marketing) articles about “big data” and “data science”. What saddens me about the whole discussion is that there is the underlying premise that what is stopping companies from “harnessing the power of big data” is just the lack of an easy-to-use, push-button tool. Respectfully, if you believe this, you should bow out of the conversation altogether.
Math is hard and stuff.
The first article that really bothered me is titled “Do Predictive Modelers Need to Know Math?” This is a provocative title from a veteran in the data mining/data science industry, and his conclusion is basically ‘Yes, but not everyone on the team needs to be able to hand-solve equations.’ I think that’s a fair point within the context of needing to understand the mathematical concepts behind algorithms, but not needing to be bogged down by notation.
Extending that idea a little further, how far away from the math should a business be comfortable with an employee pushing the button on a machine learning algorithm? Should the CEO be building predictive models? The Intern? A Call Center Rep? For me, I think the answer falls back on the allegory of the highly-specialized tradesperson:
Driver: “How can you charge $100 for five minutes work? All you did was put a bolt on and turned the wrench a few times!
Mechanic: “I didn’t charge you for the parts, I charged you for knowing where to put the wrench…”
The value a data scientist brings to a business is not that he can push the buttons in a GUI like rattle for R, Weka, KnowledgeSeeker, or SAS Enterprise Miner. What your data scientist brings to the table is knowing the underlying assumptions that go into a model, how the algorithm works, which algorithm is appropriate for the business problem being solved and when to know the model/algorithm has failed.
Of all of the things listed, the experience of knowing when the model can/has failed is what you’re paying the money for. That knowledge doesn’t come from just pushing the GUI buttons a bunch of times. And if you’re making million-dollar decisions based on an algorithm, it’s worth paying the salary for a person who really understands the model.
Hire a mathematician, get a programmer free
The next article that bothered me is a “Business Analytics: Do we need data scientists?” debate over “Do we need data scientists at all?” The No argument boils down to an idea that only things that can be made easy and are sufficiently developed are useful/valuable. Thus, because a general analyst can’t use Excel, but rather might need to write a SQL query or write a program to put together a dataset, the problem-domain is too difficult. The No debater also refers to data scientists as being “adversarial”, “pretentious”, project “snobbery”, etc.
But here’s the thing…the problem-domain isn’t particularly difficult if you hire someone with above-average math proficiency. Any decent graduate program in mathematics, statistics, computer science, economics, finance, psychology and others will be using data through programming. Now, the languages may vary between Java, R, Python, Matlab, C++, SAS, Octave, Eviews or others, but the language doesn’t matter, they’ll learn whatever language your company is using once you hire them. They also will learn the systems you are using to store your data, whether it’s a standard relational database, a NoSQL database, or a parallel processing platform like Hadoop.
How can I be certain that the math person you hire will be able to learn all that’s necessary for data science? Because the type of person who likes math & programming is probably a ‘system builder’ type of person. The type of person who played with Legos growing up. The type of person built their own desktop computer back in the day. The type of person who thinks How It’s Made is much more interesting TV than mindless reality shows. The type of person who WANTS to know how a database is storing data, what new open-source technology is out there, wants to find out how many nodes they can connect together before their program won’t finish any faster.
As far as the adversarial/pretentious/snobby comment, all I can say is I’ve never witnessed that. Everyone I know in the data science community are the nicest people, willing to share code, collaborate on ideas and talk until they lose their voice about how to solve an interesting problem.
Data Science is about innovative research, not reporting
I’ve read four academic papers this week. I’m not in graduate school.
As some of you might know, I started a new position at a startup which provides real-time intelligence for the lead generation industry. As such, I’ve got access to billions of records of unstructured data and equally as much structured data. And as a startup, there are several warts that need to be fixed with respect to data storage. So for any given day, I might go from accessing a MySQL database, Amazon Redshift (columnar RDBMS), Amazon DynamoDB (NoSQL) and plain ol’ .csv files via Excel or massive .csv files on Amazon S3. To access this data, I’ve used a combination of R, Python, SQL Workbench, and MySQL Workbench using OSX, Ubuntu desktop and a ‘headless’ Ubuntu image on Amazon EC2.
Why am I giving you about all this jibber-jabber about research papers and tools? Because the idea of building a one-size-fits-all tool to solve the problem I’m working on just doesn’t make sense. And for that matter, I’m not even sure the problem I’m working on is worth solving. But that’s the thing…I don’t KNOW it’s not worth solving, so I need to find out. I’ve got a quarter-billion URLs that I think I can extract information from, just to give our clients ONE more data element to use to optimize their marketing strategies. There may be an already existing algorithm I can use, or maybe I’ll try this research paper on “word breaking” I found from Microsoft Research. Once I find out the answer, if it’s valuable, then I need to be able to implement my algorithm into our real-time API, because it’s likely whatever language I end up using isn’t going to be what our API is written in.
So if these aren’t the type of problems you’re working on, then maybe there is an all-in-one tool out there for you to use (and that’s okay). But these are the types of edge-case problems that I think about when I think about “data science”, and as such, it will always be custom and ad-hoc. There are many awesome open-source tools I will use to help me along the way, but it will never make sense to build an easy-to-use tool for a problem a few dozen companies may ever need to know the answer to.
Use the data you have to do something extraordinary
If you don't 'get' something, own it. Don't dump your dumb garbage into the world.
I’m already 1100 words into this rant, so I’ll finish up with a few admissions. Yes, “data science” is somewhat a ridiculous name for the combination of advanced analytics and data engineering that it represents. And yes, there are plenty of vendors out there pedaling hype about the grandeur of ‘Big Data’ and why every business MUST jump on board or be left behind.
But rather than focusing on why something is “useless” or “stupid” or “hype”, just ask yourself “Can I solve the business problems I have today using the tools I currently have access to?” If the answer is yes, then great, get to work. If not, maybe you can find someone to help you get where you’re going (and that person may or may not call themselves a “Data Scientist”). Either way, let’s all move forward and do something extraordinary. It’s the least we can do for our customers.